 2016, Vol. 41
2016, Vol. 41文章信息
- 樊恒, 徐俊, 邓勇, 向金海
- FAN Heng, XU Jun, DENG Yong, XIANG Jinhai
- 基于深度学习的人体行为识别
- Behavior Recognition of Human Based on Deep Learning
- 武汉大学学报·信息科学版, 2016, 41(4): 492-497
- Geomatics and Information Science of Wuhan University, 2016, 41(4): 492-497
- http://dx.doi.org/10.13203/j.whugis20140110
-
文章历史
- 收稿日期: 2014-06-22






2. 华中师范大学物理学院, 湖北 武汉, 430079;
3. 中船重工集团公司第七二二研究所, 湖北 武汉, 430072;
4. 华中农业大学理学院, 湖北 武汉, 430079
2. Department of Physics, Center China Normal University, Wuhan 430079, China;
3. The 722 Research Institute, China Ship Building Industry Corporation, Wuhan 430072, China;
4. College of Science, Huazhong Agricultural University, Wuhan 430079, China
基于视觉的行为识别是对视频图像中人的行为进行分析和识别,是智能监控领域的一种关键技术。
目前研究行为识别的方法一般分为基于模型方法[1, 2]和基于相似性度量的方法[3, 4]。前者首先建立某种准则,然后从运动图像序列中提取目标的外形、运动等特征,根据所获得的特征信息,通过人工或半监督的方法来定义正常行为的数学模型。一般选择隐马尔可夫模型[5, 6]或图模型[7]对图像特征所表示的状态建模,然后匹配观测值与各种人体行为模型,并判断匹配结果。Dimitrios等[8]使用混合隐马尔可夫模型,绕开了目标检测和跟踪,从而实现多个场景下的人体行为识别。Zhang等[9]基于人体3D星型骨架模型,利用多角度2D人体形状描述和识别人体行为。通常情况下,如果模型能准确描述人体行为,这类基于模型的方法能够较好地识别出人体行为。而基于相似度量的方法考虑到人体行为难定义、易发现的特点,避免显示定义人体行为的数学模型。其基本原理是自动从运动图像序列数据中学习各种人体行为,根据学习结果判断测试视频中的行为类型。Meng等[10]通过GRN-BCM(gene regulatory network based bienenstock,cooper,and munro spiking neural networks model)方法构建行为模型,从而识别人体行为。Dollár等[11]通过稀疏时空特征识别人体行为。然而,这两类行为识别方法都有其自身的局限性。基于模型的方法在人体行为种类较多的情况下难以建立准确的模型。而基于相似性度量的行为识别方法需要学习大量的人体行为样本,但是在实际环境下,复杂的背景以及人体行为的多样性增加了学习难度,导致识别准确率下降。
近年来,作为机器学习邻域研究的热点问题,深度学习[12]已成功应用在图像处理、语音识别等方面。Moez等[13]通过3D卷积深度网络(3D convolutional neural networks,3D CNN)来识别人体行为。与文献[13]所提方法不同,本文提出了一种基于深度信念网络(deep belief networks,DBNs)的人体行为识别方法。深度信念网络是深度学习的一种,通过深度信念网络无监督地训练学习人体行为,从而建立深度网络模型。实验结果表明,本文提出的方法能够有效识别多种行为。
1 行为识别整体流程本文算法主要由训练与识别两个部分组成。在训练阶段,首先处理训练样本,通过高斯混合模型对背景建模,运用背景减法来提取前景,获得前景运动时的二值图像。将二值图像作为输入,通过深度学习获得各种行为的多层次特征。对低层次特征组合,构建深度信念网络。在识别阶段,利用训练得到的深度信念网络来识别各种不同行为。系统整体流程如图 1所示。

|
| 图 1 行为识别流程图 Fig. 1 Workflow of Behavior Recognition |
目前,目标检测方法主要有背景减法、光流法以及时间差分法等。时间差分法[14]一般较难提取出完整的运动目标,在运动目标内部容易产生空洞。光流法[15]的计算相对复杂,抗噪能力较差。为了实现检测的自适应性和实时性,本文选择基于高斯混合模型的背景减法[16],该方法实现简单、运算速度快,同时能够适应背景变化。
对于图像中任一像素点随时间变化的序列{X1,X2,…,Xt},基于混合高斯模型建模,当前观测点像素值的概率为:

式中,k为高斯模型的数量,通常为3~5;ωi,t为t时刻第i个高斯模型的权值,满足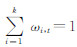 ;μi,t和Σi,t分别是t时刻第i个高斯模型的均值和方差。其中,η为高斯概率密度函数:
;μi,t和Σi,t分别是t时刻第i个高斯模型的均值和方差。其中,η为高斯概率密度函数:

考虑到计算的复杂性,通常取Σn,t=σn2I。
在实际应用中,背景通常会发生变化,因此,需要更新混合模型中各个高斯分布参数。Stauffer和Grimson[17]选择如下方法更新高斯混合模型的权值、均值和方差:

式中,ρn,t=αη(Xtμn,t,σn,t);α为学习率,表示背景的更新速度;Mn,t为模型匹配算子,当新的像素匹配时其值为1,反之为0。
图 2展示了本文算法在部分不同场景下Jog行为前景提取结果。第一行为原始视频帧,第二行为检测结果。

|
| 图 2 不同场景下前景提取图 Fig. 2 Foreground Extraction in Various Scenes |
深度学习是一种神经网络模型,由Hinton等人[12]提出。有别于传统神经网络模型,深度学习模型包含多个隐含层。如图 3所示,每个隐含层由许多相互独立的简单神经元组成,每两个隐含层构成一个玻尔兹曼机,将所有隐含层得到的玻尔兹曼机串联得到深度学习的网络模型——深度信念网络。在深度信念网络中,每个隐含层接收来自更低层的神经元的输入,通过输入与输出之间的非线性关系,将低层特征组合成更高层的抽象表示,并建立观测数据的分布式特征。通过自上而下的学习形成多层的抽象表示,且多层次的特征学习是一个自动学习过程。根据学习到的网络结构,系统将输入的样本数据映射到各种层次特征,并利用分类或者匹配算法分类识别顶层的输出单元。

|
| 图 3 深度学习的神经网络模型 Fig. 3 Neural Network Model of Deep Learning |
假设深度学习系统S包含有n层结构S1、S2、…、Sn,I是系统的输入,O是系统的输出。则整个系统可以用I→S1→S2→…→Sn→O表示,即系统的输入可以准确地用输出来描述,这表明输入I经过每一层Si未丢失信息,即任何一层Si都是原始输入信息的另外一种表示。深度学习的思想也是如此:将I作为输入层,S是中间隐含层,O作为输出层。在S中,任意两个相邻的隐含层Si和Si+1构成一个受限玻尔兹曼机(Restricted Boltzmann Machine,RBM),保证任何一层的输入都可以用输出准确或近似描述。将隐含层得到的所有受限玻尔兹曼机串联起来,从而构造出DBNs。
3.2 受限玻尔兹曼机一个玻尔兹曼机可以看作是基于能量理论函数的概率模型,根据热力学能量函数定义概率密度—玻尔兹曼分布。假设其状态随机变量为x,能量函数为E(x),那么该状态出现的概率密度分布函数表示如下:

式中, 。一个典型的玻尔兹曼机是一个无向循环图,其能量函数定义如下:
。一个典型的玻尔兹曼机是一个无向循环图,其能量函数定义如下:

式中,x是可见变量,作为输入数据;h是隐含变量;b、b′、c′、c分别是可见变量和隐含变量的阈值;W、U、V是连接节点之间的权重矩阵。对玻尔兹曼机加上不能与自身连接的约束条件,由此得到RBM,如图 4,其能量函数定义如下:


|
| 图 4 受限玻尔兹曼机 Fig. 4 Restricted Boltzmann Machine |
深度学习常用的模型有自动编码器、稀疏编码、深度信念网络等,本文选择DBNs模型。
深度信念网络是一个包含多个隐含层的概率模型,每一层从前一个隐含层获取高度相关的关联,可以看作多个RBM的累加,每个低层的RBM输出结果作为输入数据用于训练下一个RBM,通过贪婪学习得到一组RBM,这一组RBM可以构成一个DBNs,如图 5所示。Hinton等[12]认为,一个含有l个隐含层的典型DBNs可以用联合概率密度分布描述输入量x和隐含层向量h之间的关系:

式中,x=h0,P(hk|hk+2)是条件概率分布。

|
| 图 5 深度信念网络 Fig. 5 Deep Belief Networks |
由于深度学习的参变量较多,其训练算法决定了模型的训练速度和训练误差。本文选择贪婪的逐层训练算法[18]。
贪婪无监督学习算法的主要思想是对DBNs内每一层进行无监督学习,最后对整个网络进行监督学习和微调。将一个DBNs网络分层,每层由若干个神经元组成,各自独立计算来自其下一层的数据,同一层的各节点之间没有连接。深度学习的整个过程可以用图 6描述,包含预训练(pre-training)、编码解码(unrolling)和微调(fine-tuning)3个过程。在预训练阶段,下一层与上一层构成一个典型的RBM,使用无监督的学习调节网络的参数,使得RBM的输出能够准确或近似描述输入,使之达到平衡状态。然后下一层的输出作为上一层的输入,与更上层构成新的RBM,调节参数,使RBM达到平衡。如此反复,直到最后一层。使用训练得到的DBNs对目标进行识别的过程被称为编码解码。当完成无监督的训练学习后,再通过原始输入和最终的输出有监督的学习整个网络,调节每层的权重,这一过程也称为微调。

|
| 图 6 深度学习过程图 Fig. 6 Process of Deep Learning |
在贪婪学习的过程中,采用了Wake-Sleep算法思想[19]。
4 实验结果及分析 4.1 实验参数设置本文所选择的训练样本来自于KTH数据库(http://www.nada.kth.se/cvap/actions/),该数据库提供了4种场景下25个不同行人的6种行为视频:正常行走(Walk),慢跑(Jog),跑(Run),挥拳(Box),双手挥手(Wave),鼓掌(Clap)。在DBNs训练前,预处理待训练的样本数据部分结果见图 7。

|
| 图 7 训练样本 Fig. 7 Training Samples |
对于深度学习的网络模型,训练迭代次数、网络隐含层层数以及每一层所含神经元个数是3个重要参数。本文分析了这3个参数与深度学习的性能关系。分别选取训练迭代次数为20、40、60、80、100,网络隐含层层数为3、4、5、6、7,每一层神经元个数为50、100、150、200、250来训练深度学习网络,分析网络的训练误差。在隐含层层数分别为4、5、6,每层神经元个数为150时,迭代次数和训练误差的关系如图 8所示。在迭代次数为80,每层神经元个数分别为150、200、250时,隐含层层数和训练误差的关系如图 9所示。在迭代次数分别为40、60、80,隐含层层数为6时,每层神经元个数和训练误差关系如图 10所示。从实验结果可以看出,迭代次数、每层神经元个数以及隐含层层数均对深度学习的训练精度有明显影响。从图 8中可以看出,迭代次数越多,训练得到的网络越准确,同时时间开销也越高,但是随着训练次数的无限增加,网络的精度趋于稳定。同样,对于每层神经元个数与隐含层层数,也需要根据实际情况以

|
| 图 8 迭代次数与训练误差关系图 Fig. 8 Relationship Figure of Iteration Times and Training Error |

|
| 图 9 隐含层层数与训练误差关系图 Fig. 9 Relationship Figure of Hidden Layers and Training Error |

|
| 图 10 每层神经元个数与训练误差关系图 Fig. 10 Relationship Figure of Number of Nerve Cell and Training Error |
及精度要求来确定。在本文实验中,选择迭代次数为80,隐含层层数为6,每层神经元个数为200。
4.2 实验结果在训练样本集训练学习后,得到深度信念网络,通过深度信念网络对测试样本进行测试。表 1是各种行为识别的混淆矩阵。
| 行为 | Walk | Jog | Run | Box | Wave | Clap |
| Walk | 0.93 | 0.053 | 0 | 0.017 | 0 | 0 |
| Jog | 0.07 | 0.9 | 0.03 | 0 | 0 | 0 |
| Run | 0.01 | 0.02 | 0.97 | 0 | 0 | 0 |
| Box | 0 | 0 | 0 | 1.00 | 0 | 0 |
| Wave | 0 | 0 | 0 | 0 | 1.00 | 0 |
| Clap | 0 | 0 | 0 | 0 | 0 | 0.96 |
从表 1中可以看出,在6种行为中,Jog和Walk最容易混淆。由于Jog是介于Walk和Run之间的一种行为,但从行为姿态的幅度上来说,Jog更接近于Walk,因而容易造成混淆。此外,本文还将识别结果与现今主流的行为识别算法[20, 21, 22, 23]进行了比较。表 2中列出了几种算法在KTH(http://www.nada.kth.se/cvap/actional)数据集上的比较结果,从表 2中可以看出,本文所选择的深度学习模型识别效果优于其他方法。
本文提出了一种基于深度学习的行为识别方法,通过深度信念网络模型自动学习人体行为特征,从而避免人工选择各行为特征。然后通过学习所得到的网络模型分类识别人体行为。实验表明,深度学习能够较好地表达人体行为特征,相较其他人体行为识别方法,识别率得到较大提高。但是对某些相似的行为,识别效率尚待提高。
| [1] | Niu F, Abdel-Mottaleb M. HMM-based Segmentation and Recognition of Human Activities from Video Sequences[C]. IEEE International Conference on Multimedia and Expo, Amsterdam, Netherlands, 2005 |
| [2] | Zhou Hanning, Kimber D. Unusual Event Detection via Multi-Camera Video Mining[C]. 18th International Conference on Pattern Recognition, Hong Kong, China, 2006 |
| [3] | Wu Xinyu, Ou Yongsheng, Qian Huihuan, et al. A Detection System for Human Abnormal Behavior[C]. 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 2005 |
| [4] | Chen Yufeng, Liang Guoyuan, Lee K K, et al. Abnormal Behavior Detection by Multi-SVM-based Bayesian Network[C]. International Conference on Information Acquisition, Guangzhou, China, 2007 |
| [5] | Wei Xiaoli,Shen Weiming. Gabor-MRF Model Based on Color Texture Image Segmentation[J]. Geomatics and Information Science of Wuhan University, 2010, 35(8):955-958(魏小莉,沈未名. 一种基于马尔科夫随机场模型的彩色纹理图像分割[J]. 武汉大学学报·信息科学版, 2010, 35(8):955-958) |
| [6] | Yang Lujing,Wang Deshi,Li Yu. A SAR Image Shadow Modeling and Classification Method Based on HMM and Chain Code[J]. Geomatics and Information Science of Wuhan University, 2010, 35(2):215-218(杨露菁,王德石,李煜. 利用边界链编码和HMM进行SAR图像阴影建模和分类[J]. 武汉大学学报·信息科学版, 2010, 35(2):215-218) |
| [7] | Cai D, He X, Han J. Using Graph Model for Face Analysis[OL]. http://www.cad.zju.edu.cn/home/dengcai/Publication/TR/UIUCDCS-R-2005-2636.pdf, 2005 |
| [8] | Kosmopoulos D I, Voulodimos A S, Varvarigou T A. Behavior Recognition from Multiple Views Using Fused Hidden Markov Models[M]. Berlin:Springer-Verlag, 2010 |
| [9] | Zhang Fan, Guo Li, Lu Haixian, et al. Star Skeleton for Human Behavior Recognition[C]. IEEE International Conference on Audio, Language and Image Processing, Shanghai, China,2012 |
| [10] | Meng Y, Jin Y, Yin J. Modeling Activity-dependent Plasticity in Bcm Spiking Neural Networks with Application to Human Behavior Recognition[J]. IEEE Transactions on Neural Networks, 2011, 22(12):1952-1966 |
| [11] | Dollár P, Rabaud V, Cottrell G, et al. Behavior Recognition via Sparse Spatio-temporal Features[C]. IEEE International Workshop on Joint, Beijing, 2005 |
| [12] | Hinton G E, Salakhutdinov R R. Reducing the Dimensionality of Data with Neural Networks[J]. Science, 2006, 313(5786):504-507 |
| [13] | Baccouche M, Mamalet F, Wolt C, et al. Sequential Deep Learning for Human Action Recognition[M]//Human Behavior Understanding, Berlin:Springer-Verlag, 2011:29-39 |
| [14] | Abdi J, Nekoui M A. Determined Prediction of Nonlinear Time Series via Emotion Temporal Difference Learning[C]. Control and Decision Conference, Yantai, China, 2008 |
| [15] | Ning Huazhong, Xu Wei, Zhou Yue, et al. Temporal Difference Learning to Detect Unsafe System States[C]. IEEE International Conference on pattern Recognition, Tampa, USA, 2008 |
| [16] | Chen C C, Aggarwal J K. An Adaptive Background Model Initialization Algorithm with Objects Moving At Different Depths[C]. IEEE International Conference on Image Processing, San Diego, USA, 2008 |
| [17] | Stauffer C, Grimson W E L. Adaptive Background Mixture Model for Real-time Tracking[C]. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, Washington, USA, 1999 |
| [18] | Hinton G E, Osindero S, Teh Y W. A Fast Learning Algorithm for Deep Belief Nets[J]. Neural Computation, 2006, 18(7):1527-1554 |
| [19] | Hinton G E, Dayan P, Frey B J, et al. The "Wake-sleep" Algorithm for Unsupervised Neural Networks[J]. Science, 1995, 268:1158-1161 |
| [20] | Fathi A, Mori G. Action Recognition by Learning Mid-level Motion Features[C]. IEEE International Conference on Computer Vision and Pattern Recognition, Anchorage, USA, 2008 |
| [21] | Gilbert A, Illingworth J, Bowden R. Fast Realistic Multi-Action Recognition Using Mined Dense Spatio-Temporal Features[C]. IEEE International Conference on Computer Vision, Kyoto, Japan, 2009 |
| [22] | Bregonzio M, Gong S, Xiang T. Recognising Action as Clouds of Space-time Interest Points[C]. IEEE International Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009 |
| [23] | Laptev I, Marszalek M, Schmid C, et al. Learning Realistic Human Actions from Movies[C]. IEEE International Conference on Computer Vision and Pattern Recognition, Anchorage, USA, 2008 |