 2015, Vol. 40
2015, Vol. 40文章信息
- 华一新, 李响, 赵军喜, 王丽娜, 张晶
- HUA Yixin, LI Xiang, ZHAO Junxi, WANG Lina, ZHANG Jing
- 一种基于标签云的位置关联文本信息可视化方法
- A Tag Cloud-based Visualization for Geotagged Text Information
- 武汉大学学报·信息科学版, 2015, 40(8): 1080-1087
- Geomatics and Information Science of Wuhan University, 2015, 40(8): 1080-1087
- http://dx.doi.org/10.13203/j.whugis20130794
-
文章历史
- 收稿日期: 2013-12-17





现实生活中存在大量与地理位置或者区域相关联的文本信息,比如一个地方的地志,某个地点发生的新闻,以及网络上与地理位置关联的微博、微信等信息。这些信息被称为位置关联(英文中一般称之为“geo\|referenced”或者“geotagged”)文本信息。随着众包、自发地理信息等概念的流行[1],出现了大量与地理位置关联的文本信息。如何进行有效的可视化,为信息的探索和发现提供有力支持成为需要解决的问题。
传统的位置关联文本信息可视化方法主要有以地理信息为主的可视化方法和以文本信息为主的可视化方法。
传统的地理信息系统软件(如ArcGIS、SuperMap等)根据不同类型的文本信息进行可视化。结构化的文本信息作为地理要素的属性信息存储在关系表中,点击某一个地理要素时,与之关联的文本信息会以数据表格的形式呈现出来。对于非结构化的文本信息,则采用一种外部链接的方法,即该地理区域保存了所有与之关联的文本存储位置,当点击该区域时,由相应的外部程序(如记事本、浏览器等)或者内嵌在地理信息系统软件中的插件(Office,Adobe插件)打开文本。
这种可视化方法非常适合表达传统的“几何+属性”结构的地理信息,但是对于互联网中大量非结构化的位置关联文本信息,用户难以从这种可视化的形式中发现和探索有用信息。
大百科全书软件(如微软的Encarta、维基百科以及百度百科等),采用的是与地理信息系统软件截然不同的思路,以文字为主体,文字所关联的地理空间位置则由偏安一隅的地图来表示,如图 1所示。这种表示方法过于侧重表达文本信息,空间信息的表达过于简略。

|
| 图 1 以文本信息为主的可视化方法 Fig. 1 The Visualization Method for Text Information |
基于此,本文提出了一种基于标签云的位置关联文本信息可视化方法。
1 基于标签云的位置关联文本信息可视化方法作为非空间文本信息表达的有效方法,标签云(tag cloud或word cloud)最早以“潜意识文档(subconscious file)”一词出现在Douglas Coupland的《Microserfs》一书中[2],此后经Flickr网站首次应用之后便得到广泛使用。很快,标签云也用在了空间文本信息可视化中。
1.1 标签云和传统地图相结合法文献[3]最早将标签云应用到地理信息可视化研究中,根据调查报告中巴黎地标物出现词频的高低,将它们以不同大小的字体标注在巴黎地图上,形成巴黎的心理认知地图。文献[4]通过标签云的方法,将具有地理标签的海量照片信息与地图关联,并进行可视化。此后,也有学者在文献[4]的基础上利用mash\|up工具将标签和标签云叠加在地图上[5, 6]。文献[7]以新闻和科技文献为研究对象,通过标签云的方法进行地理可视化从而及时感知公众健康情况。以上方法将标签云和传统地图很好地结合,但标签云会和地图上原有的注记产生冲突,容易使用户读图困难,甚至产生错误的理解,如图 2所示。

部分研究学者注意到了标签云和传统地图结合的不足,于是省略了地图上原有的地理要素,通过标签云来填充地图。
文献[8]中绘制的“世界简史地图”,数据来源于维基百科中各国的历史文章,然后用其中最具代表性的一个单词描述一个国家,总共用176个单词通过变形和填充,绘制了一幅世界地图。这幅“世界简史地图”不仅制作精美,而且单词高度凝炼了一个国家的简史,比如中国版图就是用“Dynasty(朝代)”单词变形绘制而成。文献[9]提出了一种Taggram地图,和文献[8]的“世界简史地图”不同的是,该图用了多个单词,按照该单词在网站中的(比如Flickr)流行程度以不同字体、大小填充在相应的国家版图中。
上述两种地图虽然有不同程度的变形,但是均保留了国家版图的主要特征。由于省略了大量的地理要素,标签云和地图结合得也非常完美,标签显示非常清晰。但是上述两种方法存在以下三点不足:
(1) 两种方法均只适用于面状要素,而不适合点状要素;
(2) 文献[8]中的“世界简史地图”虽然精美,但为手绘地图,并不适合计算机自动生成;
(3) Taggram保留了行政区划形状的真实性,且里面的标签排列是随机生成的,因此标签的位置很容易让读图者产生误解。本文按照文献[9]的方法,根据百度百科中“中国”词条和中国地图形成了一幅Taggram,如图 3所示。在图 3中,读图者很容易误解“北京”是在中国的西部,也容易联想“政党”、“泥石流”和“漠河”这样的词汇是否和台湾岛存在潜在的联系。

|
| 图 3 通过百度百科“中国”词条和中国行政区划图形成的Taggram Fig. 3 A Tag Clouds in a Region of China Generated from Articles of Baidu Encyclopedia About China |
本文针对上述方法的不足,将标签云和Cartogram地图相结合,提出了一种新的基于标签云的位置关联文本信息可视化方法。
2.1 Cartogram地图Cartogram有多种中文译法,比如统计地图、拓扑图或者示意地图等,为避免歧义,本文统一称之为Cartogram。它是一种根据某种属性值将对象形状进行夸大或缩小的地图,能保持位置的相对正确,基于属性进行夸张变形,直观地传递某种特定信息。Cartogram可以分为4类:离散Cartogram,连续Cartogram,多林Cartogram(由英国利兹大学的多林发明,并以他的名字命名,又称之为圆形Cartogram,与之类似的还有矩形Cartogram)以及伪Cartogram(Pseduo Cartogram)[10, 11]。
离散和连续的Cartogram和原地图相比,尽管存在变形,但它们是在原地图的基础上根据属性值的不同对原有地理要素扩充或者缩小,而多林Cartogram则直接以圆形或者矩形取代原有地理要素。
伪Cartogram,是一种并不完全遵守Cartogram变化法则的Cartogram。最为著名的伪Cartogram由Waldo Tobler博士于1986年提出,这种Cartogram并不依据属性值对地理要素放大或者缩小,而是保持各要素变化前后的正交性(若变化前要素A在要素B的正北方,那么变化后要素A仍然要保持在要素B的正北方)的一种变形[12]。
2.2 标签云和Cartogram相结合法本文借鉴了多林Cartogram和伪Cartogram的思想,利用规则格网设计并生成了一种适合标签云叠加的Cartogram。该Cartogram将点状和面状地理要素根据不同权值转换成离散圆,同时又保持了正交性的特点,然后将标签云和这种Cartogram相结合,生成了一种新的可视化地图作品,本文将其称之为标签云地图。
以中国及其周边19个国家的百度百科词条为例,具体说明该可视化方法。图 4(a)是普通的行政区划图,以各行政区划的中心点生成离散单位圆(图 4(b)),将这些离散单位圆按照水平和垂直方向重新布局,使其不相互压盖(图 4(c)),并且保持相对位置的准确性。按照权重的不同,为离散单位圆设置大小不同的直径或者填充不同的颜色,图 4(d)是依据百度百科对各国描述的文字数量所计算的权重。然后在不同单位圆之间建立连接关系,图 4(e)中将陆上边界相邻的国家之间以直线相连。图 4(f)~4(i)是依不同比例尺对各单位圆进行显示控制,当标签云地图随比例尺放大时,首先显示出国名(图 4(f))、再依次显示出国名和50个标签(图 4(g))、国名和100个标签(图 4(h))、国名和200个标签(图 4(i))。

|
| 图 4 标签云地图实现流程 Fig. 4 Implementation of a Tag Cloud Map |
与Taggram(图 3)相比,标签云和Cartogrom相结合的方法既能适用于面状要素又能适用于点状要素。由于标签云并不按照地理要素的真实形状填充,而是统一按照圆形进行填充,避免了用户对标签位置产生误解。同时,由于保持了相对的正交性,以及采用直线相连表示邻接关系,使得地理要素的相对位置和拓扑关系得以保留。
2.3 标签云地图生成的基本流程标签云地图生成的整体流程如图 5所示。标签云地图的数据源是普通地图和与地理位置关联的文本信息。我们需要按照不同的指标(如旅游景点的点评数量、国土面积等)来生成Cartogram。由于涉及的地理要素主要是点、面要素,因此需要分别设计点要素Cartogram生成算法和面要素Cartogram生成算法。针对大量的非结构化文本信息,通过词法分析和过滤来提取关键词和相应的词频,最后依据标签位置生成算法,生成标签云地图。整个流程涉及三个核心算法,分别是Cartogram生成算法、汉语自动分词算法以及标签位置生成算法。其中汉语自动分词已经有较为成熟的商业化产品,标签位置生成算法的研究也较为成熟,已有多个商业化产品,如Wordle和Tagxedo等。

|
| 图 5 标签云地图的生成整体流程 Fig. 5 An Overall Process of Implementation of a Tag Cloud Map |
因此,本文根据标签云地图的特殊需求,以腾迅微博部分城市位置微博文本数据为实验对象,重点解决地理点要素和面要素的Cartogram生成算法以及标签位置生成算法中显示规则模型的设计。图 6是某一天全国部分大城市的标签云地图,在该比例尺条件下,显示了当天每个城市频率最高的三个词。

|
| 图 6 全国部分大城市标签云地图 Fig. 6 Top Three Words in Big Cities of China with the Tag Cloud Map Method |
用户在微博网站上发布的部分消息会同时包含其位置信息,如城市和城市街区。在小比例尺地图上,可将城市看作点状要素,在大比例尺地图上,城市街区可看作面状要素。因此,本文中Cartogram算法主要关注点状和面状要素。针对点状要素,该算法的首要规则是所有点都分布于规 则的网格交叉点上,这样便于浏览,可实现有序的可视化布局。同时,这也是与认知地图学的结论相吻合的,因为人们倾向于在水平方向或者垂直方向上来记忆位置之间的关系[13]。基于Jo和Ryu的算法思想[14],我们对原本分布密度不规则的两个相邻点之间的距离进行简化,根据两点之间夹角θ的大小,仅保留两点中X轴和Y轴方向上距离较大的点,并且将较大的距离调整为标准单位1,较小的简化为0。即 如果两个点之间水平方向的距离比较大,可以认为两个点在同一水平线上,垂直方向的距离简化为0。具体如图 7所示。

|
| 图 7 两点之间距离的简化 Fig. 7 Simplification of the Distance Between Two Points |
该算法首先进行横向压缩,然后进行纵向压缩(图 8(a)),方向从左至右、从上至下。假设 l1是一个n个X坐标相同的位置点的集合,l2是与l1在X轴上相邻的一个集合。θkhigh和θklow定义为l1上的点Vk和l2上的分别位于点Vk的上面和下面且距离Vk最近的两个点Ui-1和Ui的夹角(图 8(b))。只有当所有夹角都不小于阈值角度Θ(设为45°)时,l1和l2两个数据集合便可以压缩成相同的X值。在Y轴上重复该过程完成纵向压缩。这样就将所有位置点置于规则单元网格的交叉点上,如图 9所示。

|
| 图 8 压缩序列与定义与Θ比较的角度 Fig. 8 Compression Sequence and the Definition of Two Angles to be Comparedto Θ |

|
| 图 9 所有点的原始位置和重新调整后位置 Fig. 9 Actual Positions and Reallocated Positions of all the Points |
对于面要素,首先根据其中心点位置将所有面要素转换成点要素。然后,实施点要素的Cartogram生成算法。最后,将位置具有相邻关系的点用直线连接起来,如图 10所示。

|
| 图 10 面要素的Cartogram算法实现 Fig. 10 A Cartogram Algorithm for Area Features |

很多流行的微博网站(如新浪和腾讯)都会提供API接口。根据这些API接口,可以获取用户发布的信息。如图 11所示,我们基于腾迅微博API编写了一个小工具,该工具可以通过经纬度获取时间、地点、用户名、粉丝数量、转发数量、评论数量以及全文内容等信息,并且直接存储在本地数据库中。获取的文本数据可以直接通过现有的工具如ICTCLAS进行分词和过滤。最终可以获得文本的关键词和词频统计,如图 12所示。

|
| 图 11 获取微博信息的工具 Fig. 11 A Tool for Retrieving Messages from Microblog |

|
| 图 12 文本的关键词及词频 Fig. 12 Keywords and Their Frequency |
关于标签云的生成已经有很多成熟的算法和工具(如Wordle,Tagxedo等)。因此Cartogram和标签云结合的关键在于显示规则的设计。目前主要有两种显示规则,一种是面向不同尺度,另一种是面向不同时间。
3.3.1 面向不同尺度的显示规则该规则是用离散的模型表达不同尺度上的相同对象,如图 13所示。从国家级别到地区级别,我们设计了4种不同的离散模型(图 13(a)~13(d))。用户逐渐放大地图,比例尺越来越大,标签云显示的内容会愈加详细。首先显示出来的是所有城市,每一城市用模型一表示,接着放大至模型二,最后是模型三。如果用户继续放大至城市级别,便会显示出城市的不同地区,我们用模型四来表示。在模型四中,相邻的地区用直线连接起来。随着用户继续放大,每一个地区又会重复该过程。

|
| 图 13 使用不同的模型表达相同的对象 Fig. 13 Providing Various Models to Represent the Same Object |
当然,不同地区的信息量是有差异的,为了表示出这种差异,首先应用归一化的方法计算出每个地区所对应的标准信息量,考虑到要素之间可能产生的压盖,可采用不同的颜色来表示。
具体的计算过程如下:
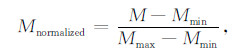
Mnormalized∈ 0,1/3 )时,模型用蓝色填充; Mnormalized∈ 1/3,2/3 )时,模型用黄色填充; Mnormalized∈ 2/3,1)时,模型用红色填充。此处M表示地区的信息量,即每个地区发表的位置微博的总条数。对于每一模型,关键字使用模型填充颜色的相近色系来表示,如图 13(d)所示。每种模型的显示级别、最大词频数和标签大小值与屏幕大小、信息载负量等多个因素有关,以各要素尽量不压盖、显示清晰为目标,给出每个模型的实验参数,如表 1所示。
| 模型 | 最大级别 | 最小级别 | 最大词频数 | 标签大小/px |
| 模型一 | 1∶19百万 | 1∶4.75百万 | 3 | 60 |
| 模型二 | 1∶4.75百万 | 1∶2.38百万 | 12 | 120 |
| 模型三 | 1∶2.38百万 | 1∶0.59百万 | 24 | 180 |
| 1∶0.59百万 | 1∶0.29百万 | 3 | 60 | |
| 模型四 | 1∶0.29百万 | 1∶0.10百万 | 12 | 120 |
| 1∶0.10百万 | 24 | 180 |
本文设计了两种时间标签云的显示方法。第一种类似于“sparkclouds”的思想[15, 16]。用户移动鼠标至某一个关键词上时,它就会浮动出来并且放大显示。文字下面的波线图表示的是在一段时间内该关键词出现的频率,如图 14所示。

|
| 图 14 波线显示的关键词出现的频率 Fig. 14 A Polyline Appears Under Text to Represent It’s Frequency of Recent Days |
第二种方法使用“瀑布”的隐喻,随时间变化的文本以瀑布飞流直下的形式分布。用户点击图上任何一个模型,右栏就会显示出一个“瀑布”式的标签云,如图 15所示。

|
| 图 15 随时间变化的“瀑布”式标签云显示 Fig. 15 Using a “Waterfall“ Methaphor to Represent Tags Change over Time |
通过该方法,我们发现了一些在普通地图或微博上都难以发现但是有趣的事情。比如,在2013年3月21日这一天,很多在北京地区的人对一个名叫孟晓苏的人很感兴趣,而很多在贵阳的人却对一个名叫张妮娜的人关注颇多,如图 16所示。在互联网上可以查找到关于孟晓苏和张妮娜的部分详细资料。

|
| 图 16 北京和贵阳在同一天的标签云 Fig. 16 Tag Clouds of Beijing and Guiyang on the Same Day |
孟晓苏是原中国房地产开发集团有限公司的总裁,他在该时间段内连续发表了很多关于国务院出台的调控楼市新“国五条”的言论。该时间段内在北京地区,孟晓苏作为一个高频词出现,可能正好反映出北京市民对于房价问题和房地产相关政策法规的关心。张妮娜是一个平面模特,于2009年走红于网络,在该时间段内她发布了一系列照片,但她仅在贵阳地区作为一个高频词出现,这很可能与她是贵阳本地人有关。
4 结 语标签云是关键词的视觉化描述,是文本分析处理结果的一种简单而高效的可视化表达方法,而地图则是表达地理位置的重要方法。因此,作为两者结合的标签云地图不仅提供了文本信息的描述,更是对地理空间数据进行表达和探索的地理可视分析的一种新尝试。它的特点总结如下: (1) 滤除了很多普通地图上不相关的细节信息,只保留了主要的信息,不同尺度下信息的详略程度不同;(2) 适用于点状要素,也适用于面状要素;(3) 标签云没有使用行政区域的轮廓,避免了由于标签位置而产生的误解;便于用户浏览与地理位置关联的文本信息,减少了一些不必要的操作,并能够帮助用户在大量的位置关联文本信息中把握信息的总体特征和趋势。
本文给出了标签云地图设计和实现整体流程,并以腾讯微博的真实数据集为例,应用全国33个城市一个月内的微博消息数据设计并实现了一个原型。但这还不足以证明该方法的有效性,今后还需要收集更多的数据继续该研究,随着数据量的增加,进一步完善显示规则模型的设计。同时,Cartogram实现算法的实施效率也有待进一步改进。除此以外,还需要通过可用性测试来评价标签云地图的可用性,以及它与传统的地图可视化方法的比较。
| [1] | Li Deren, Qian Xinlin. A Brief Information of Data Management for Volunteered Geographic Information[J].Geomatics and Information Science of Wuhan University,2010, 25(4):379-383(李德仁, 钱新林. 浅论自发地理信息的数据管理 [J]. 武汉大学学报·信息科学版, 2010, 25(4): 379-383) |
| [2] | Coupland D. Microserfs: A Novel [M]. New York: Harper Collins, 2011 |
| [3] | Milgram S. Psychological Maps of Paris [J]. Environmental Psychology: People and Their Physical Settings, 1976: 104-124 |
| [4] | Jaffe A, Naaman M, Tassa T, et al. Generating Summaries and Visualization for Large Collections of Geo-referenced Photographs [C]. The 8th ACM International Workshop on Multimedia Information Retrieval, Santa Barbara, California, USA,2006 |
| [5] | Slingsby A, Dykes J, Wood J, et al. Interactive Tag Maps and Tag Clouds for the Multiscale Exploration of Large Spatio-temporal Datasets[C]. The Information Visualization, 11th International Conference, California, USA, 2007 |
| [6] | Wood J, Dykes J, Slingsby A, et al. Interactive Visual Exploration of a Large Spatio-temporal Dataset: Reflections on a Geovisualization Mashup [J]. Visualization and Computer Graphics, IEEE Transactions on, 2007, 13(6): 1 176-1 183 |
| [7] | Maceachren A, Stryker M, Turton I, et al. Health GeoJunction: Place-time-concept Browsing of Health Publications [J]. International Journal of Health Geographics, 2010, 9(1): 23-26 |
| [8] | Elmer M. Laconic History of Our World Map[OL]. http://maphugger.com/post/38323044556/laconic-history-of-the-world-2012-my-first,2012. |
| [9] | Dinh-Quyen N, Schumann H. Taggram: Exploring Geo-data on Maps through a Tag Cloud-Based Visualization [C]. The 14th Information Visualisation (IV) International Conference, London, 2010 |
| [10] | Tobler W. Thirty Five Years of Computer Cartograms [J]. Annals of the Association of American Geographers, 2004, 94(1): 58-73 |
| [11] | Dorling D. Area Cartograms: Their Use and Creation[OL]. http://www.dannydorling.org/wp-content/files/dannydorling_publication_id1448.pdf,2013 |
| [12] | Tobler W R. Pseudo-Cartograms [J]. Cartography and Geographic Information Science, 1986, 13(1): 43-50 |
| [13] | Tversky B. Distortions in Memory for Maps [J]. Cognitive Psychology, 1981, 13(3): 407-433 |
| [14] | Hyungeun J. Placegram: A Diagrammatic Map for Personal Geotagged Data Browsing [J]. IEEE Transactions on Visualization and Computer Graphics, 2010, 16(2): 221-234 |
| [15] | Lee B, Riche N H, Karlson A K, et al. SparkClouds: Visualizing Trends in Tag Clouds [J]. IEEE Transactions on Visualization and Computer Graphics, 2010, 16(6): 1 182-1 189 |