 2015, Vol. 40
2015, Vol. 40文章信息
- 李继园, 甘斌, 孟令奎, 张文, 段红伟
- LI Jiyuan, GAN Bin, MENG Lingkui, ZHANG Wen, DUAN Hongwei
- 云环境下时序遥感影像的快速缓存切片方法
- Rapid Imagery Tile Generation for Remotely Sensed Time-series Data in the Cloud Environment
- 武汉大学学报·信息科学版, 2015, 40(2): 243-248
- Geomatics and Information Science of Wuhan University, 2015, 40(2): 243-248
- http://dx.doi.org/10.13203/j.whugis20130079
-
文章历史
- 收稿日期:2013-04-25




2. 武汉大学遥感信息工程学院, 湖北 武汉 430079
2. School of Remote Sensing and Information Engineering, Wuhan University, Wuhan 430079, China
影像瓦片式缓存技术通过数据采样建立多级静态WMS (Web map service),实现基于在线的影像多尺度区域快速访问[1],广泛用于数据现势性较弱的GIS应用,如土地变更和资源调查。在环境监测中,通常采用高时间分辨率影像对大范围或重点区域进行近实时或短周期观测,如震区或灾情的多时相航拍任务或卫星遥感数据采集。该类数据呈现“流式”传输以及动态更新特性,给海量影像瓦片式缓存中多级切片的构建效率带来了很大挑战。
当前此类切片在单机上执行时间较长,而利用集群执行并行切片是一种有效途径,如ArcGIS Serve[2]和Map Tiler[3]。然而,此类实现中,计算节点通过集中式共享存储系统并行访问数据执行处理(即移动数据到计算节点),易导致网络I/O瓶颈,扩展性受到限制[4]。此外,一次性批处理模式也无法满足近实时或短周期的WMS发布需求。近年来,快速发展的云计算并行编程模式Map-Reduce(MR)通过本地化计算(即移动计算到数据节点)与数据并行思想,实现上千个普通计算节点的扩展能力[5]。该模式通过映射(Map)和规约(Reduce)函数实现大规模数据并行操作,其复杂性(容错性、任务分配、工作流控制)由MR自动处理。目前,一些学者已尝试将其应用于大规模遥感影像处理,并取得较好的加速性能[6, 7]。文献[8]在该模式下提出将底层4个影像切片映射成相同key,传输到Reduce端合并,建立自底至顶的静态影像金字塔构建方法。但该方法未能顾及本地化计算原则,在任务迭代中产生大量数据传输,减少了并行构建的加速优势。文献[9]则以单幅文件为并行粒度进行批处理式金字塔构建,但没有考虑数据的实时接收情况,对云资源利用和数据本地化计算的优化也讨论不多。
基于上述问题,利用MR聚集的分布式计算资源研究通过多个小批量MR切片任务的动态合理分配,实现在实时或短周期内接收数据情况下的快速影像缓存切片。该分配方法围绕MR本地化计算特性,利用数据动态划分机制与基于空间相邻的上载机制对缓存切片算法进行优化,以满足动态监测对瓦片式缓存的及时性需求。
1 影像时序缓存切片快速构建方法 1.1 基本思路
Map-Reduce是一种大规模数据批处理计算模式,以key-value数据集为输入,执行以下步骤:① 对数据源分块,交给多个Map任务,并根据某种规则将数据分类,写入本地磁盘;② Reduce阶段执行多个Reduce任务,每个任务从多个Map任务节点收集具有相同key的中间结果(即数据Shuffle),合并处理并输出结果[6]。
基于该模式的简单影像并行切片策略是以单景数据为并行粒度执行批处理,即每个Map按照确定的缓存格网生成每景数据的多级切片。然而,在动态监测中,数据按时序接收且具有流式特征,简单模式并不能满足及时性需求。如图 1所 示,本文在固定时间间隔 (time window,TW) 内分配新接收的分景数据至云环境中(包括数据划分和优化上载),并在满足一定条件下(如达到某可用计算资源数)提交该TW内的数据,从而执行数据块粒度的该批次切片计算,并及时发布为WMS,即以时间上连续的多个小批量MR任务实现时序影像的切片。上述思路基于分块情况下的MR切片算法,研究每个TW内的任务分 配方法 (包括数据划分与上载),以发挥MR本地化计算优势。

|
| 图 1 Map-Reduce云环境下时序影像缓存切片生成流程 Fig. 1 Workflow of Time-series Image Tile Generation in Map-Reduce Environment |
全球剖分格网将全球地表划分为无缝连接的地理单元,是影像缓存的基本切分规则与基础。本文以Plate Carree投影下2n+1×2n划分的空间信息多级格网[10]为缓存切片格网。其第一层为2(经度方向)×1(纬度方向)格网,对该格网进行四叉树划分,可得到细分格网。在第n级划分时,每个切片经度间隔为xtile=360.0/n,纬度间隔为ytile=90.0/ n。地理范围为[xmin,ymin,xmax,ymax]的影像D在该层的切片数目Numn可由式(1)得出。其中,numx和numy分别为经度和纬度方向上的切片行列数。每个切片可用切片层次和切片在该层格网中的行列号编码〈n,row,col〉来唯一标示,其中,row和col可由式(1)推导得出。
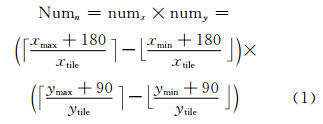
TW内的所有数据上载至云中后,形成输入key-value数据集{(T_boxi,rasBlocki)|i∈[1,n]},key为T_box,由影像接收时间T和数据块的地理范围 xmin,ymin,xmax,ymax 组成,value则为分块栅格值rasBlock。在上述格网支持下,每景影像各级切片任务将在Map与Reduce两个阶段内完成,如图 2所示。Map阶段,每个Map读取一个分块,基于上述缓存格网对分块数据依次完成所有层次的切片任务。由于格网线与分块线不一定重合,会造成数据分块边缘部分出现不完整切片 (称为碎片)。图 2中,A、B、C、D是划分后的4个数据块,由n层格网剖分线切片后,分块对角出现a、b、c、d四个碎片(称为角接碎片(jointed angle fragment,JAF));分块线接边出现e、f两个碎片(称为边接碎片(jointed edge fragment,JEF));切片g称为完整切 片(full tile)。其中,完整切片将直接过滤输出到目标地址,而JAF和JEF将作为中间key-value数据集传输至Reduce端进行最终合并。其输出key为碎片所在完整切片的时空标识元组〈T,n,row,col〉,value值为碎片栅格。

|
| 图 2 Map-Reduce缓存切片示意图 Fig. 2 Image Tile Generation Using Map-Reduce Method |
Reduce阶段,每个Reduce收集具有相同切片标识 (key值) 的JAF或JEF碎片,执行空间合并并输出到目标地址。其输出key值为切片标识,value值为切片栅格。两个阶段的描述如算法1所示,其中Combine阶段为Map阶段后的本地Reduce过程,可紧凑Map输出,减少传输量。
算法1 Map-Reduce缓存切片算法
//box为分块地理范围,block为分块栅格
Map (string Tbox,tiff block)
For all l∈level [1,…,n]do
//TileBox函数生成切片地理范围集
For all tileTbox∈TileBox(Tbox) do
tile ← Tiling(block,tileTbox) //切片函数
If tile is fulltile
Output(tile)
Else
Emit(<T,l,row,col>,tile)
//SpatialCombine为空间合并函数
Combine/Reduce (<T,l, row,col>,[tile1,…,tilen] )
fulltile ← NULL
For all tile∈[tile1,…,tilen] do
fulltile ← SpatialCombine(fulltile,tile)
If ([tile1,…,tilen] is JAF ∧|[tile1,…,tilen] EQ 4)
Output(fulltile)
ElseIf ([tile1,…,tilen] is JEF ∧|[tile1,…,tilen]| EQ 2)
Output(fulltile)
Else
Emit(<T,l,row,col>,fulltile)
1.3 时序缓存切片下的Map-Reduce任务分配
1.3.1 数据动态划分机制
1) 预估数据分块数
上述Map和Reduce阶段中,计算资源(CPU和内存)按照预设配额划分为若干单元(称为Map Slot和Reduce Slot),且每个单元分配一个Map或Reduce任务。在将所有单元视为均质的基础上,可采用规则划分法以实现计算负载均衡。一个TW内的数据划分粒度需综合考虑当前云中可用计算资源量及数据量,步骤如下。
步骤1 预估缓存数据的切片总数目。设TW内接收数据集为 {D},对于影像D在第n层缓存格网中的切片数目Numn由式(1)计算,影像D建立M到N层缓存服务的切片总数为Numtile=
步骤2 根据当前云中运行的拥有I (为减少资源竞争,限定I=3)个共享 Job的队列Q和Map Slot的总数目TNummap,预估云中可用Map Slot数如式(2)所示。其中,Q.jobi.Nummap为Q中第i个Job的Map Slot需求数;αi为该Job的Map函数任务完成率。
步骤3 设集群中单机环境下单个缓存切片平均串行生成时间为Ttile,进一步根据步骤1所得的TNumtile获得单个Map函数初始执行时间预估值,即Tmap= TNumtile×Ttile /Numpart。
步骤4 设h为Map运行时间阈值(限定为30 s),执行算法2,取最终Numpart为数据集从第M层到第N层缓存过程的划分数。该算法基于当前可用资源数,保证在Tmap不小于阈值 (限定为30 s ) 的条件下尽可能减小数据划分粒度。设影像D的数据量在数据集中所占的比重为λ,则其分块格网划分数为 Numpart×λ 。
算法2 Numpart确定算法
TotalNumtile←∑{D}D.Numtile // 预估切片总数
Numpart←ANummap //初始化为可用Map Slot数
//预估每个map阶段执行时间
Tmap← TotalNumtile×Ttile /Numpart
While(Tmap≤h)
Numpart←Numpart-1 // 减小划分数
Tmap← Numtile×Ttile /Numpart
2) 确定最优划分规则
确定单景数据划分数后,需研究合理的划分规则。上述切片算法显示分块与格网剖分线不一致使得Map阶段输出碎片,产生中间传输以及Reduce合并任务,对性能有显著影响。在数据量和分块数不变的情况下,通过分块规则优化可减少Map阶段碎片。常用规则划分法有等间距行划分、列划分及格网划分。
假定数据在剖分格网中的切片行列数分别为定量Numx和Numy,分块总数为定值Numpart,分块格网中的行列数分别为变量Numxpart和Numypart,且Numxpart×Numypart=Numpart;切片长宽都为2k,则在建立第n层缓存切片时,碎片区域面积可由式(3)计算得到:
式(3)可进一步转化为:
即分块行列比要与剖分格网上的行列比保持一致。因此,当Numpart不变时,分块行列比越接近,剖分格网行列比将产生越少的碎片数据量。
1.3.2 基于空间相邻的数据上载机制
数据本地化计算最好的状态是数据与处理任务在同一节点,其次是数据与处理任务在同一个Rack。在典型的MR环境中,计算节点即存储节点。若空间相邻的数据块分布于同一节点或同一Rack,可大大减少Map到Reduce的数据传输量。然而上述模型中数据的物理分布没有顾及空间邻近性,因此,空间相邻的碎片需要跨节点或Rack合并,从而影响MR本地化优势。
本文引入Hilbert空间填充曲线(http://en.wikipedia.org/wiki/Hilbert_curve)描述影像分块间的空间关系,将二维数据分布转换到一维空间中,并在数据上载时以此序列指导数据的物理分布,同时结合各节点处理性能进行负载均衡,直接干预计算调度。如图 3所示,分块为Numxpart×Numypart的数据上载前可建立Hilbert曲线(log2 max Numxpart,Numypart 阶),形成Hilbert排序数据块,并按以下方法上载至各节点(根据§1.3.1,有Numpart≤ANummap)。
1) 遍历每个Rack中节点上的可用Map Slot,将Hilbert曲线经过的数据块逐个上载至每个Map Slot中。
2) 若当前Rack已装满,则继续上载剩余数据块至下一个Rack,重复步骤1,直至所有数据块上载完毕。
以上方法在保证数据量与计算能力匹配的同时,也减少了从Map到Reduce阶段中数据跨节点或Rack的传输开销,使得shuffle时间复杂度 由O M2 降为O M (M表示 Map任务数)。
2 实验分析
基于 Hadoop0.20.2建立分布式计算环境,存储系统采用已集成MR本地化计算特性的GFarm 2.5.7 (http://datafarm.apgrid.org),利用Java和GDAL(http://www.gdal.org)开发了实验原型系统。利用 GFarm支持POSIX的特性,将分布式存储目录挂载为统一的本地文件系统,然后基于Socket传输技术实现§1.3.2中指定计算节点的数据传输。硬件环境为普通PC建立的集群 (1 Gb/s理论网速,10个计算节点,1个管理节点,各节点配置两个双核2.0 GHz CPU和4 GB RAM)。每个计算节点配置2个Map Slot,1个Reduce Slot。采用美国路易斯安那州2005年飓风灾情Landsat监测影像集为实验数据,以ArcGIS Server以及文献[9]提出的缓存切片算法(称为BottomUp) 对比了本文方法(称为OptMethod)的总体性能,并测试了单项性能,切片大小为256像素×256像素。
2.1 总体性能对比
执行两组实验,图 4(a)为采用2倍递增量的一组数据,测试对比三种方法(OptMethod、ArcGIS Server和BottomUp) 在满节点平台上执行7~14层切片的时间开销;图 4(b)采用1.5 GB单景数据,测试随节点增加,三种方法执行前述处理的时间开销。其中,ArcGIS Server集群部署于同一计算环境中,且所有数据预先上载至GFarm,所有测试执行3次取均值。
图 4(a)显示,随数据量增加,BottomUp开销迅速增长,该算法从Map端传输大量切片到Reduce端,造成较多网络及磁盘I/O开销。由于MR自身延迟,数据增长初期,ArcGIS Sever效率明显较高,当数据量达到384 MB,开始低于OptMethod。这是由于在低速环境下各节点的ArcSOC(ArcGIS Server服务进程)同时访问GFarm,造成较大的网络延迟,OptMethod缓慢增长,且性能最优。图 4(b)显示,随节点增长,ArcGIS Server扩展能力受到I/O限制,而OptMethod逐渐发挥出本地化计算优势,在满节点时的执行效率分别达到ArcGIS Server的1.3倍和BottomUp的3.6倍。该实验验证了本文方法在大数据量情况下具有较好的加速性能和可扩展性。
图 5测试在连续输入5景数据情况下(每景数据量约1.5 GB,输入速率为750 MB/min),ArcGIS Server (以连续的单批处理任务模拟时序数据处理) 与OptMethod(TW=2 min)执行前述处理时,各节点的平均CPU利用率(包括System、User和IO wait)。结果显示,ArcGIS Server的CPU利用率变化较大,出现“波峰”(数据切片压力较大时域),负载不够均衡。而OptMethod的资源动态分配和前后多个Job交叠执行使得其CPU负载更为均衡,降低了处理延迟。以上TW值为人为调整值,实验同时考察了不同TW大小对缓存切片的时间开销影响,具体如下:分别调整TW为0.5、1、2、3、4 min,测试数据接收量至10 GB时,OptMethod切片的执行时间分别为1 354、1 240、1 189、1 285和1 417 s。结果显示,在TW=2 min时,执行时间最少,在TW≥3 min之后,逐渐增长,分析其原因为前后批次Job间的重叠率逐渐减少,未充分利用计算资源。当TW过小(≤1 min)时,将产生更多的小粒度Job,易导致软件调度开销增大。如何优化调整TW,有效利用计算资源是下阶段重点研究的内容。
为测试§1.3.1中划分数预估方法的有效性,采用图 5中TW=2 min的测试为实验场景。以三组固定数据量(32、64和128 MB)的划分情况做对比,记录每组的执行时间,并通过Hadoop shell组件获取执行任务的JVM内存消耗 ,统计Job的平均内存利用率,如表 1所示。结果显示,128 MB划分法的内存利用率最小。由于执行粒度大,该方法在处理前期的资源利用率并不充分,后期单个任务延迟较长,因此开销增大。32 MB划分粒度过小,增大了线程管理与调度对内存和CPU的压力,执行效率也并不理想。64 MB划分开销最接近预估法。但由于预估法可根据云中资源量实现数据动态划分,对内存的利用也更加充分。
为了测试数据分块规则对切片性能的影响,在无上述优化情况下,采用数据量为2.9 GB的影像 (剖分格网行列比为3/4) 生成第15级缓存切片(分块总数为20),记录2×10、10×2 、5×4和4×5四组分块的切片时间(包括划分开销Partition与上载开销、切片过程中的Map/Shuffle/Reduce开销以及总开销)。其中,数据划分与上载采用两个线程,轮流顺序读取数据块并上载至相应节点测试三次取均值。图 6显示,四组测试中,划分(均值为35 s)及上载开销 (均值为88 s) 变化很小,说明在数据量一定的情况下,不同划分法对划分与上载开销的影响差异不大。由于数据量和并行度不变,四组方法的Map开销均相差不大。由上文可知,4×5划分法最接近此数据剖分格网行列比,因而产生较少的碎片、传输量及Reduce任务量。结果也显示该法的Shuffle和Reduce阶段开销较小。相反,10×2分块法产生了大量的碎片面积,导致整体性能较低。理论上,若切片级别提高1级,Map阶段的碎片面积也将提高4倍,此时4×5划分法更能体现优化性能。
基于上述分块机制,对同一实验数据生成第15级切片,测试数据上载方法对生成性能的影响(优化前采用轮询法)。两组测试记录Map、Shuffle和Reduce阶段任务数的变化情况,同时统计Map阶段任务在云环境中的分布状况,如图 7所示。测试执行3次取均值。优化前,Map阶段有7个跨节点的任务,1个跨Rack任务;而优化后,Map阶段只有2个跨节点任务,没有跨Rack的任务。这是由于优化后,各节点按Map Slot数分配数据块,实现较为均衡的负载,避免了部分跨节点或Rack的处理任务分配。此外,因为上载到相同节点的数据块具有较好的空间邻近性,Map阶段产生的碎片可在本地合并,从而输出碎片数从26 584个减少到18 692个。图 7显示,两组测试中,优化后的Map阶段时间开销显著减少,而Shuffle阶段和Reduce阶段的任务量也明显降低,总体开销也缩短了95 s 。
针对当前高时空分辨率影像的缓存切片生成效率较低的问题,本文利用云计算并行编程模式Map-Reduce聚集计算资源,提出一种在时序影像持续抵达情况下的快速缓存切片方法,从而为短周期获取影像的瓦片式WMS提供及时更新。实验证明,该模型在低速网络环境和大数据量情况下具有较好的扩展性能和加速性能。未来将研究利用流式Map-Reduce以重叠Map和Reduce阶段,进一步减少计算延迟。
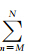 Numn,设影像D的Numtile记为D.Numtile,进一步计算分景数据集的切片总数目TNumtile=∑{D}D.Numtile。
Numn,设影像D的Numtile记为D.Numtile,进一步计算分景数据集的切片总数目TNumtile=∑{D}D.Numtile。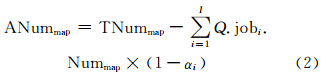
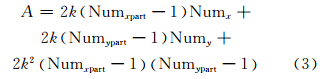
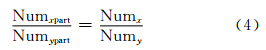

图 3 基于Hilbert排序的数据上载优化
Fig. 3 Optimization of Data Uploading Based
on Hilbert Curve

图 4 三种缓存切片方法总体性能对比
Fig. 4 Performance Comparison of the Three Tiles
Generation Methods

图 5 面向时序影像缓存计算的节点CPU平均利用率变化
Fig. 5 Changes of Average CPU Utilization When
Generating Time-series Image Tiles
32 MB 64 MB 128 MB 预估法
执行时间/s 1 197 985 1 250 930
总分块数/个 238 120 60 109
Job内存利用率/% 61.1 54.5 48.2 59.7

图 6 不同数据格网分块情况下的执行时间对比
Fig. 6 Execution Time Comparison of Data Partitions
in Different Grids

图 7 数据上载优化前后Map/Shuffle/Reduce
任务数对比
Fig. 7 Numbers of Map/Shuffle/Reduce Before and
After Data Uploading
| [1] | WMS Tile Caching[EB/OL]. http://wiki.osgeo.org/wiki/WMS_Tile_Caching, 2013] |
| [2] | ArcGIS ServerMap Cache[EB/OL]. http://blogs.esri.com/Dev/blogs/arcgisserver/archive/2010-/09 /13/ArcGIS-Server-10.0-improvements-to-map-cac- he-tile-generation.aspx, 2013 |
| [3] | MapTiler Cluster[EB/OL]. http://help.maptiler-.org/cluster, 2013 |
| [4] | Huang He. Analysis and Optimization of Massive Data Processing on High Performance Computing Architecture[D]. Changsha:National University of Defense Technology in China, 2011(黄訸.高性能计算体系结构下的海量数据处理分析与优化[D]. 长沙:国防科学技术大学, 2011) |
| [5] | Dean J, Ghemawat S. MapReduce:Simplified Data Processing on Large Clusters[C]. The 6th Symposium on Operating Systems Design and Implementation, USENIX, Berkeley, 2004 |
| [6] | Golpayegani N, Halem M. Cloud Computing for Satellite Data Processing on High End Compute Clusters[C]. IEEE International Conference on Cloud Computing, Bangalore, 2009 |
| [7] | Ermias B T. Distributed Processing of Large Remote Sensing Images Using MapReduce[M]. Saarbrücken:LAP Lambert Academic Publishin, 2011 |
| [8] | Huo Shuming.Research on the Key Techniques of Massive Image Data Management Based on Hadoop[D]. Changsha:National University of Defense Technology in China, 2010(霍树民.基于Hadoop的海量影像数据管理关键技术研究[D]. 长沙:国防科学技术大学, 2010) |
| [9] | Liu Yi, Chen Luo, Jing Ning, et al. Parallel Batch-Building Remote Sensing Images Tile Pyramid with MapReduce[J]. Geomatics and Information Science of Wuhan University, 2013, 38(3):278-282 (刘义, 陈荦, 景宁, 等.利用MapReduce进行批量遥感影像瓦片金字塔构建[J]. 武汉大学学报·信息科学版, 2013, 38(3):278-282) |
| [10] | Li Deren, Xiao Zhifeng, Zhu Xinyan, et al. Research on Grid Division and Encoding of Spatial Information Multi-Grids[J]. Acta Geodaetica et Cartographica Sinica, 2006, 35(2):52-70(李德仁, 肖志峰, 朱欣焰, 等. 空间信息多级格网编码研究[J].测绘学报, 2006, 35(2):52-70) |