 2015, Vol. 40
2015, Vol. 40文章信息
- 许峰, 尹峻松, 黄立威
- XU Feng, YIN Junsong, HUANG Liwei
- 一种基于软件网络的重要服务发现方法
- A Software Network-based Important Service Discovery Method
- 武汉大学学报·信息科学版, 2015, 40(11): 1557-1562
- Geomatics and Information Science of Wuhan University, 2015, 40(11): 1557-1562
- http://dx.doi.org/10.13203/j.whugis20130662
-
文章历史
- 收稿日期: 2013-11-08






2. 中国电子设备系统工程公司研究所, 北京, 100141
2. Institute of Electronic Equipment System Engineering Corporation, Beijing 100141, China
21世纪初,伴随着万维网的迅速发展和(语义)Web服务技术的兴起,软件的形态、应用模式以及设计开发方法都发生着显著的变化[1]。Web服务技术已成为面向服务架构(service-oriented architecture,SOA)的主流实现方式,基于SOAP(simple object access protocol)协议的Web服务和基于REST(representational state transfer)架构[2]的Web API(application programming interface)是目前互联网上的两类主流Web服务[3, 4, 5, 6, 7, 8, 9, 10, 11]。
发现合适的服务是实现服务共享、复用的重要前提,其质量会影响到服务组合的相容性和可替换性,关系到能否真正实现服务的“即插即用”。到目前为止,已有很多种Web服务发现的方法被提出,包括基于QoS(quality of service)约束的服务发现[11, 12, 13, 14, 15, 16, 17, 18, 19, 20]、基于(本体)语义的Web服务发现[12, 20]、基于情境推理的服务发现[13]等经典方法。最近,有研究者[8, 14]开始尝试以此着手研究服务的分类和组合等问题,实验结果表明,在测试集上的效果优于一些传统的经典方法,为本文的工作提供了研究基础。
网络科学的快速发展[4],为我们提供了研究复杂软件系统结构及行为的有力工具。Oh等[9, 10]对Web服务的描述文件WSDL(Web services description language)进行了多粒度的分析,在不同的网络模型中均验证了“小世界”(small world)和“无标度”(scale free)的特性,并认为上述发现将有助于改进现有的Web服务发现和组合方法。由于互联网上可用的公共Web服务资源有限,数据的收集和分析存在一定困难,与前面介绍的工作相比,Web服务方面还鲜有实证研究。
作为一类由Web API构建的面向服务的软件,从拓扑结构的角度研究其复杂性、稳定性、可靠性等特性,以及Web API资源的分类和推荐等问题,是一种基于“软件网络观”的研究新思路[6, 7]。实证研究表明,这些系统具有“小世界”和“无标度”等复杂网络特性[8],会影响其运行、维护和二次开发等重要活动。根据Web API组合的历史记录,构建相应的网络模型,通过分析其中节点的重要性和鲁棒性(抗攻击性),以及节点之间产生链路的概率,解决服务质量保障中重要服务及其潜在可组合服务发现的问题。因此,本文主要是采用“软件网络观”,从Web API间依赖关系的角度出发,提出一种识别重要服务及与之可进行组合的服务的方法,将这些服务推荐给开发者作为面向服务的软件系统的基础构造块,提高开发效率、降低开发成本。
1 网络构建和特性分析通过简单的编程,可以将不同的Web API糅合成新的网络应用(Mashup),由于操作便捷,这种方式受到很多IT公司和开发者的推崇。例如,将Google地图的API和Foursquare地理信息服务的API组合起来,就能形成一个根据用户所处的地理位置推荐餐厅的新服务。随着越来越多的IT公司在互联网上开放自己的API,针对个性化的用户需求,Mashup的数量也在不断增长,构成了一类重要的面向服务的软件系统。
USPS Tracking、100 Most Powerful Celebrities和allSongsBy是著名的programmableweb.com网站上注册的3个Mashup。其中,USPS Tracking由USPostalService和Google Maps 两个API组合而成;100 Most Powerful Celebrities由Google Maps、Yahoo Geocoding和YouTube 3个API组合而成;allSongsBy由YouTube和iTunes and iTunes Connect 两个API组合而成。图 1(a)显示了这3个Mashup(依次标记为1~3)与上述Web API(依次标记为1~5)之间的构成关系。如果两个Web API曾组合成1个Mashup,那么它们之间添加1条(无向)连线。根据上述规则,可以将Mashup-API二分图转换成图 1(b)所示的Web API网络,其中边代表真实的组合历史。

|
| 图 1 Web API网络示例 Fig. 1 Example of Web API Networks |
以文献[6]提供的数据集(包含654个节点、8 494条边)为基础,分析了其中的最大连通子图(包含573个节点、7 838条边),其拓扑如图 2(a)所示,系使用开源软件工具Cytoscape[15]生成。该网络的平均最短路径为2.385,平均集聚系数为0.679,表现出很明显的“小世界”特性;节点的度分布大致服从幂指数为-0.847的幂律分布,如图 2(b)所示,表明虽然大多数的节点的度都很小,但有少数节点拥有较大的连边数,这说明其对应的Web API经常与其他API组合形成新的Mashup。

|
| 图 2 实验案例的网络图和节点度分布 Fig. 2 Case of Complex Network and Node Degree |
现有的基于网络的方法[6, 14]在研究服务的重要性时,是将其映射为网络中节点的重要性来进行分析。传统的图论中,节点的度、接近度(closeness)、介数(betweenness)等指标均可以用来从某一侧面度量(相对)重要性,但这些指标在计算时都未考虑节点之间的相互影响;而且除度外,接近度、介数的计算复杂度都较高。此外,PageRank[16]及其改进算法通过“打分”的方式也可以用来量化等级或重要性,却忽略了节点的局域特性[8],即除极少数通用的服务外,服务的重用与组合具有领域特性,而不可能是全局性的。本文方法通过社区划分、角色分析来发现局域中心节点和与其他社区链接的门户节点,借助可组合性分析哪些服务可与重要服务进行组合(图 3)。

|
| 图 3 方法的主要流程 Fig. 3 Main Flow of the Presented Method |
在网络中,节点的局域性体现于它属于特定的社区(community),在这样的社区中,内部节点链接紧密而社区之间链接稀疏。社区结构是网络模块化与异质性的反映,同类的节点倾向于聚集在一起,而不同类的节点之间很少有链接。这种社区与基于标签(tag)内容聚类形成的(主题)社区不同,是根据Web API之间实际的组合历史来划分的,因而更容易分析哪些是重要服务,哪些更可能相互组合。
社区发现是复杂网络中的一个研究热点,目前已有一些学者根据不同的策略提出了不少经典的方法,而模块度(modularity)指标被较为广泛地用于评价社区划分的好坏。针对大规模实际网络的实验表明,Newman等人提出的算法[17]能较好地发现网络中存在的社区,且时间复杂度仅为O(n·lg2n),但是容易产生少数规模巨大的社区。因此,综合考虑模块度、时间复杂度和社区规模,选择文献[18]中的一种改进算法对§2中构造的网络进行社区划分,形成如图 4所示的8个规模各异的社区,最大的包含179个节点、最小的包含3个节点。

|
| 图 4 社区划分结果 Fig. 4 Result of Community Partition |
在社会网络分析领域,结构等价(structural equivalence)和块模型(block model)被用来对网络进行(分类)划分,但由于约束条件苛刻,不太适用于真实的大规模网络。针对图 4所示的5个规模较大的社区,考虑到其组织形式各异,需要进一步分析在局域范围内,不同节点所扮演的(结构)角色。在本文中,根据节点之间的相互链接,把具有相似结构特征的节点(如中心节点、桥接节点等)归为一类,表示为角色。
由于划分了社区,可以从社区内和社区间的链接两个方面来定义角色相应的指标:中心性(centrality)和链接性(interconnectivity)。中心性主要用于度量节点链接到社区内其他节点的紧密程度,反映出节点在局域范围内的重要性;链接性主要用于量化节点链接到外部社区的紧密程度,反映出节点在不同社区间连通的重要性。社区 mi中节点i的(局域)中心性指标为:

式中,ki表示该节点链接到该社区中其他节点的边数; kmi表示该社区中所有节点的k的平均值;σkmi表示该社区中k的标准偏差。c值越大,表明节点在社区中越处于中心节点的地位。
类似地,mi中节点i的链接性指标[19]为:
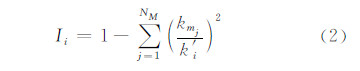
式中,k′ i表示节点i的链接度;kmj表示节点i链接到社区mj中所有节点的边数。如果节点的边都分布在一个社区内,那么其I值为0。
根据文献[19]定义的角色分类,图 4中5个规模较大社区的节点对应的角色如图 5所示。分析发现:① 除了少量的中心节点(属于R5),其他大多数的节点都属于R1和R2,这与网络的“无标度”特征比较符合;② 网络中大多数的节点都只与其社区内的节点链接,而少数节点(属于R2、R3和R7)则负责社区间的链接;③ 随着节点链接度的增加,其最近邻居(nearest neighbors)的平均链接度的值呈下降趋势,表明度-度呈负相关性;④ 有趣的是R7类节点(如Google Maps、Flickr、Twitter)之间却相互链接,导致网络的平均最短路径较小;⑤ 度小的节点很难作为社区的门户节点,事实上网络中也无R4类节点。

|
| 图 5 网络中节点角色分布图 Fig. 5 Distribution of Node’s Role |
进一步地,图 6显示了网络中规模最大社区的节点角色情况:R1类节点只与本社区内的节点进行链接,扮演普通“土著人”的角色;R2类节点与外界有少量链接,充当“信息传递者”的角色;R3类节点与外界有较多链接,扮演“信息中转者”的角色;R5类节点是社区中的中心节点,充当局域“行政长官”的角色;R7类节点拥有较大的链接度并且与外界有较多联系,扮演社区“门户”的角色。这样,可以将复杂的 Web API间组合关系简化为(有限的)角色间的关联,比单一的节点重要性指标能更全面地分析网络中重要的节点。

|
| 图 6 带角色标识的社区网络 Fig. 6 Community Network with Role Tag |
鉴于本文所构建网络的特点,其中任意长度的路径实际上就是一个潜在的面向服务的应用。考虑到该网络的平均最短路径仅为2.385,路径长度越大,这些Web API能组合的概率就会越低。因此,构造一个新的这种应用需要依据一定的规则对网络进行遍历,主要包括:① 优先选择各个社区中中心性高(R5~R7类)的节点;② 如果构造面向单一主题(针对同一社区)的应用,优先与R5类节点进行链接,否则与其邻居中按度降序排列的前k%(k值由用户设定)的节点进行链接;③ 如果构造面向多主题的混合应用,优先与本社区中的R7类节点进行链接,否则与其邻居中按度降序排列的前k%的节点进行链接;④ 文献[8]的实证研究发现,API节点之间的路径长度一般小于等于组成一个Mashup的API的个数。
因此,服务的可组合性问题就可以转化为:对于任意给定的n(n ≥ 2)个Web API,对其中任一节点 对<ns,ne>,根据上述规则,是否能寻找以ns为起点、ne为终点,且包含(除ns和ne外)其他给定API对应节点的路径,该路径长度尽可能小于等于n。使用Dijkstra最短路径算法可在O((|V|+|E|)lg|V|) (n << |V|)内求解该问题,如不存在这样的路径,则表明基于 Web API组合的历史记录,给定的API无法进行组合以形成一个新的应用。
基于上述规则,进一步分析了图 4所示的5个主要社区,挖掘出各社区的R5类和R7类节点及其之间的链接,形成了整个网络的骨干网(Backbone),即网络中最重要的节点所组成的一个连通子网,而该子网代表了网络的整体特征。如图 7所示,Google Maps、Flickr、del.icio.us、Youtube、Digg等知名的Web API均出现在骨干网中,表明要形成一个新的Mashup,其对应的路径应尽可能包含图 6所示的这些节点。

|
| 图 7 服务社区骨干网 Fig. 7 Backbone of Service Community Network |
ProgrammableWeb是一个著名的Web服务管理网站,文献[8]收集并整理了其上注册的大量Mashup和Web API。针对其中的Mashup,每次随机选取100个,来分析每个Mashup包含的API在本文构建的网络中是否存在前述的路径,以验证可组合性分析的合理性。由于本文构建的Web API网络的规模和文献[8]并不一致,随机选取的Mashup中如果包含该网络中没有的API,则忽略不做分析。重复实验10次、50次和100次的结果,如图 8所示。实验结果表明,随着实验次数的增加,匹配成功率稳定在98%左右,且偏差较小。进一步分析发现,这些Mashup中有超过95%的Web API包含在图 7的骨干网中,说明这些API确实可作为构造新Mashup的基础构件。

|
| 图 8 可组合性验证结果 Fig. 8 Evaluation Result of Composable Services |
进一步地,针对本文提出的方法、度排序、接近度排序、介数排序和PageRank等5种方法,使用Kendall’s tau[20]来计算上述方法得出的结果序列与ProgrammableWeb上实际结果的相似性(相似性越高表明越接近真实结果),如表 1所示,其中Top-k表示根据该方法得到的排名前k个服务。表 1的结果表明,针对本文给出的数据集,PageRank较其他传统的社会网络分析方法有一定的优势,但在整体表现上不如本文提出的方法更贴近实际效果。
| 方法 | Top-10 | Top-20 | Top-50 | Top-100 |
| 度排序 | 0.654 | 0.683 | 0.674 | 0.665 |
| 接近度排序 | 0.432 | 0.459 | 0.449 | 0.421 |
| 介数排序 | 0.501 | 0.518 | 0.506 | 0.495 |
| PageRank | 0.782 | 0.812 | 0.834 | 0.821 |
| 本文方法 | 0.806 | 0.827 | 0.832 | 0.836 |
Web API是一种新兴的Web服务,根据它们之间的组合历史记录,依据“软件网络”的思想,本文首先构建了一个API网络模型,其中边是API之间的组合关系(以构造新的Mashup),分析了网络的整体特性,验证了Web服务网络具有复杂网络“小世界”和“无标度”特征。进一步地,提出了一种重要Web API的发现方法,主要包括网络社区划分、社区中节点角色分析,以及指定API集的可组合性分析3个步骤。针对ProgrammableWeb数据的实验结果表明,该方法在分析给定API集的可组合性方面,匹配成功率高达98%;同时,挖掘出的骨干网中的节点在95%的Mashup中出现,表明它们可以作为构造新的Mashup的基础构件。
本文所构建的Web API网络是非加权网络,而在实际的服务组合中,服务之间的组合次数其实也是可以加以考虑的。因此,进一步的工作是,构建加权的Web API网络,提出新的算法来为用户推荐可组合新的Mashup的API集,并结合用户的使用习惯,更准确地进行推送。
| [1] | Yu Jian, Han Yanbo. Service-Oriented Computing: Principle and Application[M]. Beijing:Tsinghua University Press, 2006(喻坚, 韩燕波. 面向服务的计算——原理和应用[M]. 北京:清华大学出版社, 2006) |
| [2] | Fielding R T. Architectural Styles and the Design of Network-based Software Architectures [D]. Irvine:University of California, 2000 |
| [3] | Pautasso C, Zimmermann O, Leymann F. Restful Web Services vs. “Big” Web Services: Making the Right Architectural Decision [C]. International World Wide Web Conference, Beijing, China, 2008 |
| [5] | Lewis T G. Network Science: Theory and Applications [M]. New York: John Wiley Sons Inc, 2009 |
| [6] | Pan Weifeng, Li Bing, Shao Bo, et al. Service Classification and Recommendation Based on Software Networks[J]. Chinese Journal of Computers, 2011, 34(12): 2 355-2 369(潘伟丰, 李兵, 邵波, 等. 基于软件网络的服务自动分类和推荐方法研究[J]. 计算机学报, 2011, 34(12): 2 355-2 369) |
| [7] | He Keqing, Ma Yutao, Liu Jing, et al. Software Networks[M]. Beijing: Science Press, 2008(何克清, 马于涛, 刘婧, 等. 软件网络[M]. 北京:科学出版社, 2008) |
| [8] | Yutao M, Keqing H, Bing L, et al. Empirical Study on the Characteristics of Complex Networks in Networked Software[J]. Journal of Software, 2011, 22(3): 381-407(马于涛, 何克清, 李兵, 等. 网络化软件的复杂网络特性实证[J]. 软件学报, 2011, 22(3): 381-407) |
| [9] | Oh S C, Lee D, Kumara R T. Effective Web Service Composition in Diverse and Large-scale Service Networks [J]. IEEE Transactions on Services Computing, 2008, 1(1): 15-32 |
| [10] | Kil H, Oh S C, Elmacioglu E, et al. Graph Theoretic Topological Analysis of Web Service Networks[J]. World Wide Web, 2009, 12(3): 321-343 |
| [11] | Ran S. A Model for Web Services Discovery with QoS [J]. ACM SIGecom Exchanges, 2003, 4(1): 1-10 |
| [12] | Klusch M, Fries B, Sycara K P. Automated Semantic Web Service Discovery with OWLS-MX [C]. International Joint Conference on Autonomous Agents and Multiagent Systems, Hakodate, Japan, 2006 |
| [13] | Feng Zaiwen, He Keqing, Li Bing, et al. A Method For Semantic Web Discovery Based on Context Inference[J]. Chinese Journal of Computers, 2008, 31(8): 1 354-1 363(冯在文, 何克清, 李兵, 等. 一种基于情境推理的语义Web服务发现方法[J]. 计算机学报, 2008, 31(8): 1 354-1 363) |
| [14] | Chen Shizhan, Feng Zhiyong, Wang Hui. Service Relations and Its Applications in Service-Oriented Computing[J]. Chinese Journal of Computers, 2010, 33(11): 2 068-2 083(陈世展, 冯志勇, 王辉. 服务关系及其在面向服务计算中的应用[J]. 计算机学报, 2010, 33(11): 2 068-2 083) |
| [15] | Smoot M, Ono K, Ruscheinski J, et al. Cytoscape 2.8: New Features for Data Integration and Network Visualization [J]. Bioinformatics, 2011, 27(3): 431-432 |
| [16] | Page L, Brin S, Motwani R, et al. The Page Rank Citation Ranking: Bringing Order to the Web [R]. Technical Report, Stanford InfoLab, 1998 |
| [17] | Clauset A, Newman M E J, Moore C. Finding Community Structure in very Large Networks [J]. Physical Review E, 2004, 70(6): 66-111 |
| [18] | Wakita K, Tsurumi T. Finding Community Structure in Mega-scale Social Networks [C]. International World Wide Web Conference, Alberta, Canada, 2007 |
| [19] | Guimerà R, Amaral L A N. Functional Cartography of Complex Metabolic Networks [J]. Nature, 2005, 433(7 028): 895-900 |
| [20] | Kendall M. A New Measure of Rank Correlation [J]. Biometrika, 1938, 30 (1/2): 81-89 |