 2015, Vol. 40
2015, Vol. 40文章信息
- 陈善学, 尹修玄, 杨亚娟
- CHEN Shanxue, YIN Xiuxuan, YANG Yajuan
- 基于码字匹配和引力筛选的半监督协同训练算法
- Semi-Supervised Collaboration Training Algorithm Based on Codeword Matching and Gravitation Selecting
- 武汉大学学报·信息科学版, 2015, 40(10): 1386-1391,1408
- Geomatics and Information Science of Wuhan University, 2015, 40(10): 1386-1391,1408
- http://dx.doi.org/10.13203/j.whugis20130840
-
文章历史
- 收稿日期: 2014-07-10






高光谱图像地物分类在军事、医疗和灾害防护等领域中有十分重要的地位[1]。 分类是一个复杂的数据处理过程,分类方法的选择是关系分类成功与否的关键因素[2]。高光谱图像分类方法主要有监督分类、非监督分类和半监督分类三大类[3, 4, 5, 6, 7]。而现有的半监督学习方法主要有基于图的方法、低密度区域分割和生成式模型等[8, 9, 10]。
文献[11]中提出了半监督学习模式的协同训练(Co-training)算法,它是利用标记和交叉验证未标记数据的方法提高传统监督学习的性能。但是算法中要求两个视图充分冗余的条件限制了该方法的实际运用[12]。在此问题上,Nigam等研究了不具有充分冗余视图条件的协 同训练算法的性能,实验结果表明,如果随机将属性集大的标记样本集划分为两个视图,从而代替充分冗余的条件,同样可以得到较好的协同训练结果[13]。另一种算法DCPE Co-training[14]研究了在两个基分类器之间加入多样性分析和类概率估计,以获得更好的分类效果。Tri-training算法[15] 进一步放松了Co-training约束条件,摒弃充分冗余视图条件,利用训练集的差异性来训练基分类器,并且采用投票的方式避免大量的误差累积[16]。Huang等在高光谱图像分类时利用灰度共生矩阵和马尔科夫随机场方法提高Tri-training的精度[17]。Zhang等人提出了改进的Simple-Tri-training和Edit-Tri-training算法[18]。其中,Simple-Tri-training算法采用两个不同的训练分类器,而Edit-Tri-training算法采用数字编辑技术,得到了更好的分类结果。但是该算法单纯使用像元之间的欧氏距离最邻近作为筛选标准,忽略了像元之间的相关性对基 分类器分类结果筛选和最终分类的性能产生的贡献。Liu等人将转移学习引入到Tri-training算法,提出了机器转移学习的协同训练方法[19]。Bender等人提出将Tri-training算法的学习条件放宽[20]。另外,Okabe等人提出将K均值用于解决协同训练中的约束问题[21]。
本文采用多视图理论增加协同训练分类算法中基分类器的独立性,对基分类器的分类结果进行编码,采用码字匹配的方法取代置信度比较,进一步通过引入引力筛选机制防止误差累积。
1 典型协同训练算法 1.1 Co-training算法文献[11]中的Co-training算法本质上是一个交叉训练(cross training)的过程,算法训练集的数据必须满足以下冗余视图条件:①对同一目标的刻画可以提取两个相互独立的数据集;②两个数据集都能够充分描述该目标。算法中假定的两个子视图条件是相互独立的,如果不符合这样的假设,一个基分类器判断为置信度高的样本加入到另一基分类器中就没有意义,也就不能起到优化训练其他分类器的作用。实际实验中的数据自身并不具备这样的条件,这就导致算法在迭代训练中的精度受到影响。
1.2 Tri-training算法Tri-training算法为了避免交叉验证带来的耗时和误差累积问题,对未标记样本置信度的估计采用三个分类器隐形投票的方式。算法摒弃了Co-training算法增量式的学习方式,它的未标记数据集的大小始终不变。文献[15]给出了Tri-training算法在PAC(probably approximately correct)框架下的性能分析。定义第t轮迭代时基分类器噪声率为 et,标记训练集规模大小为 |Lt |。算法只要满足式(1),它在迭代中的学习就是进步的。
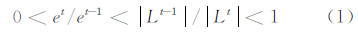
在Tri-training算法中,由于三个基分类器的差异性仅由对训练集不同的抽样决定,所以基分类器之间的相关性依然很强,造成分类器的泛化性能低。并且算法在对未标记数据分类标记时采用隐式投票的方式,没能有效防止误分数据进入迭代,对最终的分类效果影响很大。
2 推荐算法1——基于码字匹配的协同训练分类算法参考文献[15],假设已标记数据集L和未标记数据集U,基分类器hi(i=1,…,CNl),其中N为类别数目,l为基分类器分类的类别数。根据多视图理论,各基分类器采用不同的激励函数。通过L构造基分类器的初始训练样本集:将标记样本集按照类别划分为N个子集Ln(n=1,…,N),Ln按不重复穷尽排列的方式组合成初始训练集Trainseti(i=1,…,CNl)。Trainseti训练对应的hi后,将已标记样本x(x∈L)并行输入基分类器hi,则x得到CNl个分类标记mark。将mark编成一位码code={0,1,2,…,l-1}。顺序排列各位码,定义为一个码字codeword,得到k(k≤|L|)个码字。如属于不同类别的x经此过程得到了同一codeword,将此codeword删除,codeword数目变为p(p≤k)个。这p个码字构成初始码书codebook。在循环迭代中,首先测量hi的误分率ei(i=1,…,CNl)。U通过分类器,将每个样 本得到的codeword与当前codebook中的codeword对比,匹配的样本类别标注为codebook中的对应类别。如式(2)所示,定义匹配率r,其中match是本轮迭代中码字匹配的样本数。

该码字匹配的样本加入到训练集Trainseti中。新的训练样本中,标记类别不同的样本codeword重复时,codeword占有率高的类别得到该codeword,则codebook中codeword为k个或p+w个(w为增加的codeword个数)。使用更新的Trainseti训练hi。当满足式(3)所示的相邻两轮迭代条件,继续学习。
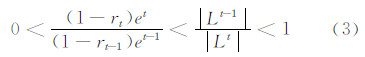
迭代退出时,保存当前训练好的分类器hi和codebook。未标记样本通过hi得到codeword,与codebook匹配,标注样本类别;否则,该样本类别随机设置。
参考文献[15]的方法,证明式(3)是训练集更新的充分条件。
证明 在PAC框架下,算法相邻两轮迭代中,分类器假设的错分率与训练集的大小和噪声率间的关系如式(4)和式(5)所示:
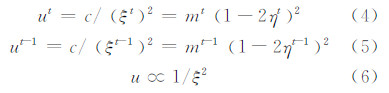
式中,c为常数;ξ为分类器的错分率;m为训练集大小;η为训练集噪声的上限值。在t轮迭代中,分类器hi对应的训练集的噪声率ηt如式(7)所示。令基分类器的平均噪声为 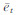 ,则式(7)可化为式(9)的形式。
,则式(7)可化为式(9)的形式。
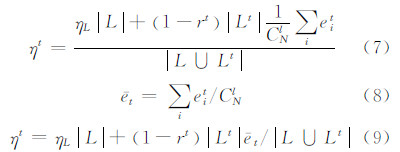
式(3)条件成立等价于|Lt|>|Lt-1|>0和(1-rt)e-t|Lt|<(1-rt)et-1|Lt-1|同时成立。由|Lt|>|Lt-1|>0可推得|L∪Lt|>|L∪Lt-1|,即mt>mt-1。结合(1-rt) et|Lt|<(1-rt-1) t-1 Lt-1 ,推出ηt<ηt-1,进而可得mt(1-2ηt)2>mt-1(1-2ηt-1)2,即ut>ut-1。根据式(6),则有ξt<ξt-1,证毕。
算法流程如下:
1) 输入已标记数据集L和未标记数据集U;
2) 初始化:组合已标记数据集L,得到Cnl个初始训练集Trainseti(i=1,…,CNl),e′ i=0.5,codebook=Φ,l′=0,r′=0;
3) Trainseti训练基分类器hi;
4) 将每个标记样本分别通过训练好的子分类器分类,一个子分类器得到一个分类结果,记为一位标记mark;
5) 将同一样本得到的CNl个mark转换为CNl位码按子分类器排列顺序,组合各位码,得到该样本当前分类结果所对应的码字codeword;
6) 所有标记样本的码字集合形成码书,删除码书中重复的所有码字,得到系统的初始码书;
7) 判断是否存在新的未标记样本加入L,若存在,进行下一步;若不存在,进入步骤12);
8) 每个测试样本依次通过排列好的子分类器hi,一个样本得到CNl个分类标记mark,按照上述方法将分类标记转换为码字,计算噪声率ei=MeasureError(hi);
9) 判断测试样本码字是否与码书码字匹配,若匹配,测试样本类别为码书码字类别,且将测试样本加入到对应类别的训练集中;
10) 计算匹配率r,判断是否满足条件(1-r)· e|L|<(1-r′) ′|l′|,若满足,updatei=TRUE,进行下一步;若不满足,updatei= FALSE;
11)L∪Li更新学习hi:e=e′,l′=|L|;r′=r,返回步骤3),继续迭代;
12 )随机设置未进入训练集的测试样本类别。
对比文献[15],本文提出的基于码字匹配的协同训练分类算法增加了基分类器数目;结合了多视图理论;将编码技术引入协同训练,用于取代简单的隐式置信度比较;在每次迭代中,所有未标记数据进入机器学习,而不是只有一部分未标记数据,扩大了学习范围。在迭代过程中,基于码字匹配的协同训练分类算法,对于每一未标记样本而言,会经过 Cn-1l-1个相关基分类器(该基分类器的初始训练集中有与未标记样本类别相同的样本)和Cnl-Cn-1l-1个非相关基分类器。这样的设计可以 使该样本在相关基分类器分类时提高每个相关基分类器的分类精度,并且在非相关基分类器分类时充分挖掘该样本与其余类别样本间的相关度。算法采用码字匹配的实质是在最终划分未标记样本的类别前,将当前基分类器的分类结果映射到码字,实现分类结果的糊化和抽象化。
3 推荐算法2——基于码字匹配和引力筛选的协同训练分类算法基于码字匹配的协同训练分类算法在一定程度上解决了Co-training和Tri-training泛化性能低和基分类器相关性高的问题,提高了分类效果。而在误差累积问题上,算法的效果对比Co-training和Tri-training算法没有太大提升。在协同训练中加入筛选机制可以进一步解决这个问题。
本文将物理学中的万有引力公式(如式(10)所示)引入筛选机制。引力常量 G调整为训练集各类别分布比例Gn(n为类别总数);质量的积m1m2转化为目标像元与某类训练集光谱平均值的积;距离r2代表图上目标像元与某类训练集聚类中心的距离。如式(11)所示,定义第t轮迭代中的筛选率为vt,其中分母为码字匹配样本数,分子为筛选样本数,那么训练集更新的充分条件可以用式(12)表示。
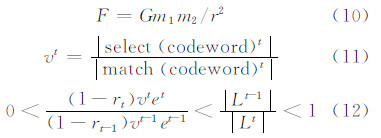
算法流程在推荐算法1的基础上进行了补充,即在步骤2)中加入类别分布比例参数初始化Gn=1/N;步骤8)中使用式(10)计算样本与各类别中心引力;步骤10)中使用式(11)计算筛选率,且计算Trainseti的聚类中心ci、光谱平均值m2i,将条件(1-r)e|L|<(1-r′)e′|l′|改变为(1-r)·ev|L|<(1-r′) ′v′|l′|,其余步骤保持不变,就完成了推荐算法2的流程。
引入万有引力筛选机制可以很好地避免误差累积,并保证算法的收敛速度。
4 实验及结果分析为了统一实验平台,本文仿真实验软件为MATLAB R2011a,操作系统为Windows XP,处理器为Intel Pentium Dual CPT T3200 2.00 GHz。实验数据采用1992年6月拍摄的美国印第安纳州印第安农林高光谱遥感试验区(AVIRIS)的一部分。图像大小为144×144,共220个波段(见图1),16类标记地物。选取其中的Corn-notill、Grass/Trees、Soybeans-min、Woods四种地物信息作为分类目标
。

|
| 图 1 AVIRIS高光谱数据 Fig. 1 AVIRIS Hyper Spectral Image Data |
实验中选取神经网络分类器作为基分类器。基分类器参数设置如下:最大迭代次数为200次,隐含层节点数根据经验公式  (m为隐含层节点数,n为输入层节点数,l为输出层节点数)计算得出。基分类器在t轮迭代的噪声率采用文献[15]中的方法,采用初始训练集在迭代中测试得到。实验在选取5%、10%和20%样本作为初始训练集的三种情况下,使用生产者精度、用户精度、总体精度和Kappa系数四种参数综合评估Co-training、Tri-training和本文推荐的两种算法。实验还计算出了每次迭代的精度,以说明误差在四种算法中的累积情况。实验结果如表1、表2和图2所示。
(m为隐含层节点数,n为输入层节点数,l为输出层节点数)计算得出。基分类器在t轮迭代的噪声率采用文献[15]中的方法,采用初始训练集在迭代中测试得到。实验在选取5%、10%和20%样本作为初始训练集的三种情况下,使用生产者精度、用户精度、总体精度和Kappa系数四种参数综合评估Co-training、Tri-training和本文推荐的两种算法。实验还计算出了每次迭代的精度,以说明误差在四种算法中的累积情况。实验结果如表1、表2和图2所示。
| % | |||||
| 抽样率 | Class | Co-training | Tri-training | 推荐算法 1 | 推荐算法 2 |
| 生产者精度/用户精度 | 生产者精度/用户精度 | 生产者精度/用户精度 | 生产者精度/用户精度 | ||
| 5 | Corn-notill | 100/2.94 | 100/5.22 | 100/13.39 | 100/14.50 |
| Grass/Trees | 17.12/77.68 | 28.41/97.17 | 35.78/98.07 | 38.86/98.66 | |
| Soybeans-min | 66.24/32.30 | 78.81/65.73 | 79.57/78.60 | 83.01/86.54 | |
| Woods | 87.74/99.84 | 95.15/99.75 | 96.97/99.84 | 97.75/99.84 | |
| 10 | Corn-notill | 100/21.50 | 100/29.05 | 100/34.66 | 100/38.40 |
| Grass/Trees | 25.06/87.27 | 31.34/86.93 | 39.33/89.28 | 50.76/89.11 | |
| Soybeans-min | 78.41/59.23 | 81.76/71.35 | 80.91/78.82 | 85.46/94.87 | |
| Woods | 92.16/99.65 | 88.61/100 | 88.87/99.83 | 92.92/99.83 | |
| 20 | Corn-notill | 100/29.01 | 100/33.25 | 100/38.89 | 100/43.03 |
| Grass/Trees | 29.42/89.26 | 34.01/89.49 | 43.77/91.95 | 51.96/91.95 | |
| Soybeans-min | 81.71/75.23 | 84.55/83.08 | 86.91/92.76 | 87.11/97.28 | |
| Woods | 93.31/99.70 | 93.49/99.70 | 94.76/100 | 95.30/100 | |
| 抽样率 | Co-training | Tri-training | 推荐算法 1 | 推荐算法 2 |
| 整体分类精度/Kappa系数 | 整体分类精度/Kappa系数 | 整体分类精度/Kappa系数 | 整体分类精度/Kappa系数 | |
| 5 | 45.22%/0.33 | 62.31%/0.60 | 69.81%/0.67 | 73.51%/0.71 |
| 10 | 62.00%/0.57 | 69.06%/0.65 | 73.87%/0.72 | 81.71%/0.81 |
| 20 | 70.63%/0.68 | 75.25%/0.73 | 81.32%/0.80 | 84.38%/0.84 |

|
| 图 2 算法在不同抽样率和迭代次数下的分类精度 Fig. 2 Classification Precision of Learning Algorithm in Different Sampling Ratio and Iterations |
由表1可以看出,推荐算法1除在初始训练集为10%时,Soybeans-min和Woods的生产者精度分别比Tri-training算法低0.85%和3.29%,其余平均分别高出两种算法6.31%和2.57%。推荐算法2的生产者精度则全部高于Co-training和Tri-training算法,且平均分别高出两种算法9.33%和6.42%。同时在表1中,推荐算法1除在初始训练集为10%时,Woods的用户精度比Tri-training算法低0.17%,其余平均 分别高出两种算法11.88%和4.61%。推荐算法2除在初始训练集为10%时,Woods的用户精度比Tri-training算法低0.17%,其余平均分别高出两种算法15.01%和7.75%。由表2可以看出,推荐算法1的总体分类精度平均分别高出两种算法12.38%和6.13%,Kappa系数平均分别高出两种算法0.2和0.07。推荐算法2的总体分类精度平均分别高出两种算法21.30%和10.99%,Kappa系数平均分别高出两种算法0.26和0.13。
由图3可以看出,推荐算法修正了经典算法的分类错误。由图2可以看出,在初始训练集为5%、10%和20%的情况下,Co-training算法的精度随着迭代次数的增加而有所下降,这是由于实验中初次随机选取的标记数据集中存在混合像元所导致的机器学习轨迹偏离;Tri-training算法的精度随着迭代次数的增加也会略有下降,说明迭代过程中出现了误差累积问题。而推荐算法1和推荐算法2的总体精度随着迭代次数的增加而趋于平稳,说明算法有效避免了迭代中误分样本对下一次迭代造成的影响,且推荐算法2在此问题上的效果更好。

|
| 图 3 抽样率为20%时各种方法的分类结果 Fig. 3 Classification Results with 20% Sampling Ratio |
本文提出的基于码字匹配的协同训练分类算法使用更多的基分类器挖掘数据之间的关系,引入多视图理论在没有增加算法的复杂度和保证协同训练的收敛性的同时增加了基分类器之间的差异性,提高了整体泛化性能;采用编码与码字匹配方式排除了置信度阈值经验性设置引入的误差。通过实验验证,对比传统的Co-training和Tri-training算法,基于码字匹配的协同训练算法具有更好的分类性能。而加入引力筛选机制的算法有效地避免了算法迭代过程中误差累积的问题,实验中获得了更好的效果,说明基于码字匹配和引力筛选的半监督协同训练算法在高光谱图像分类中具有良好的性能。
| [1] | Wang Y, Chen S, Zhou Z H. New Semi-supervised Classification Method Based on Modified Cluster Assumption[J]. IEEE Transactions on Neural Networks and Learning Systems, 2012, 23(5): 689-702 |
| [2] | Shen W, Wu G, Sun Z, et al. Study on Classification Methods of Remote Sensing Image Based on Decision Tree Technology[C]. IEEE International Conference on Computer Science and Service System (CSSS), Nanjing,China,2011 |
| [3] | Niu D, Wang F, Chang Y, et al. An Improved Multi-objective Differential Evolution Algorithm[C]. The 24th IEEE Chinese Control and Decision Conference (CCDC), Taiyuan,China,2012 |
| [4] | Yan W, Yang W, Sun H, et al. Unsupervised Classification of PolInSAR Data Based on Shannon Entropy Characterization with Iterative Optimization[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2011, 4(4): 949-959 |
| [5] | Wang Y, Chen S. Safety-Aware Semi-Supervised Classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2013, 24(11): 1 763-1 772 |
| [6] | Xiong Biao, Jiang Wanshou, Li Lelin. Gauss Mixture Model Based Semi-Supervised Classification for Remote Sensing Image [J].Geomatics and Information Science of Wuhan University,2011, 36(1): 108-112(熊彪,江万寿,李乐林.基于高斯混合模型的遥感影像半监督分类[J]. 武汉大学学报·信息科学版,2011, 36(1): 108-112) |
| [7] | Yan Li, Nie Qian, Hu Wenyuan,et al. Rapidly Computing Satellite Gravity Gradient Observations Along Orbit from Gravity Field Model [J].Geomatics and Information Science of Wuhan University, 2009, 34(2): 183-186(闫利,聂倩,胡文元,等.基于对象级的ADS40遥感影像分类研究[J]. 武汉大学学报·信息科学版,2009, 34(2): 183-186) |
| [8] | Wang Y, Chen S, Zhou Z H. New Semi-Supervised Classification Method Based on Modified Cluster Assumption[J]. IEEE Transactions on Neural Networks and Learning Systems, 2012, 23(5): 689-702 |
| [9] | Xiong B, Jiang W, Zhang F. Semi-Supervised Classification Considering Space and Spectrum Constraint for Remote Sensing Imagery[C]. The 18th IEEE International Conference on Geoinformatics, Beijing,China,2010 |
| [10] | Dopido I, Li J, Plaza A, et al. Semi-Supervised Classification of Hyperspectral Data Using Spectral Unmixing Concepts[C]. IEEE Tyrrhenian Workshop on Advances in Radar and Remote Sensing (TyWRRS), Naples, Italia,2012 |
| [11] | Yan J, Yun X, Wu Z, et al. Online Traffic Classification Based on Co-training Method[C].The 13th International Conference on Parallel and Distributed Computing, Applications and Technologies, IEEE Computer Society, Beijing,China,2012 |
| [12] | Du W, Phlypo R, Adali T. Adaptive Feature Split Selection for Co-training: Application to Tire Irregular Wear Classification[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC,2013 |
| [13] | Nigam K, Ghani R. Analyzing the Effectiveness and Applicability of Co-training[C].The 9th International Conference on Information and Knowledge Management, McLean, VA, 2000 |
| [14] | Xu J, He H, Man H. DCPE Co-training: Co-training Based on Diversity of Class Probability Estimation[C]. The IEEE International Joint Conference on Neural Networks (IJCNN), Barcelona,Spain,2010 |
| [15] | Zhou Z H, Li M. Tri-training: Exploiting Unlabeled Data Using Three Classifiers[J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 17(11): 1 529-1 541 |
| [16] | Du Bo, Zhang Liangpei, Li Pingxiang, et al. A Constrained Energy Minimization Method in Sub-pixel Target Detection Based on Minimization Noise Fraction [J].Journal of Image and Graphics, 2009, 14 (9):1 850-1 857(杜博,张良培,李平湘,等.基于最小噪声分离的约束能量最小化亚像元目标探测方法[J].中国图像图形学报,2009, 14 (9):1 850-1 857) |
| [17] | Huang R, He W. Using Tri-training to Exploit Spectral and Spatial Information for Hyperspectral Data Classification[C]. IEEE International Conference on Computer Vision in Remote Sensing (CVRS), Xiamen,China,2012 |
| [18] | Zhang Yan, Lv Danju, Wu Baoguo. Research of Semi-Supervised Classification Algorithm Based on Tri-training [J].Computer Technology and Development, 2013, 23(7): 77-79(张雁, 吕丹桔, 吴保国. 基于 Tri-Training 半监督分类算法的研究[J].计算机技术与发展, 2013, 23(7): 77-79) |
| [19] | Liu X, Zhang H, Cai Z, et al. A Tri-training Based Transfer Learning Algorithm[C].The 24th IEEE International Conference on Tools with Artificial Intelligence (ICTAI), Athens,Greece,2012 |
| [20] | Bender T, Kjaer T W, Thomsen C E, et al. Semi-Supervised Adaptation in Ssvep-based Brain-computer Interface Using Tri-training[C].The 35th IEEE Annual International Conference of Engineering in Medicine and Biology Society (EMBC), Osaka,Japan,2013 |
| [21] | Okabe M, Yamada S. Clustering with Extended Constraints by Co-training[C]. IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology (WI-IAT), Macau,China,2012 |