 2015, Vol. 40
2015, Vol. 40文章信息
- 李佳田, 康顺, 李晓娟, 张蓝, 罗富丽, 白建军
- LI Jiatian, KANG Shun, LI Xiaojuan, ZHANG Lan, LUO Fuli, BAI Jianjun
- 宽泛地理注记的投放模型
- Putting Model for Broad Geographic Annotation
- 武汉大学学报·信息科学版, 2015, 40(1): 20-25
- Geomatics and Information Science of Wuhan University, 2015, 40(1): 20-25
- http://dx.doi.org/10.13203/j.whugis20130365
-
文章历史
- 收稿日期:2013-07-28




2. 陕西师范大学旅游与环境学院, 陕西 西安, 710062
2. College of Tourism and Environmental Sciences, Shanxi Normal University, Xi'an 710062, China
地理注记是地图符号的重要组成类型之一。地图学中对地理注记的普通解释是,作为一种地图语言说明地图上所表示的地物名称、位置、范围、高低、等级(主次)等[1]。就注记内容分析,其主要形式是结构化数据的单词或数值,然而,地图服务环境赋予地理注记更多的内涵,通常以自然语言文字描述为主要形式来表达地理现象。地理注记是空间位置与内容的复合体。学术界关于地理注记的研究主要集中在三个方面:① 以地理实体命名为目标的注记体系和标注规范研究[2,3,4];② 以解决注记内容叠置或优化布置的制图综合方法研究[5,6];③ 栅格扫描地图中的注记识别方法研究[7]。
现阶段,多数网络地图环境提供具有典型众包模式特征的地理注记服务。在这种应用模式中,受众不再单纯地作为地图服务使用者,更为重要的是,其同时是数据或信息的提供者。随着地理标注服务的深入应用,受众提供的数据量必将呈几何级数增长。维护地理注记数据准确性,人工干预效率低下,迫切需要一个有效地对地理注记适宜性进行评价的方法。目前鲜见这方面的研究工作。本文通过将传统地理注记扩展为宽泛地理注记,将网络环境中的标记行为理解为投放过程,分解为投放的是什么、投放到哪里及将其投放到这里是否合适三个步聚,形式化投放过程并建立地理注记投放计算模型,用以解决地理注记适宜性评价问题。 1 宽泛地理注记
地理注记分为名称注记、数字注记与说明注记三种类型,其构成元素包括字体、字级、字色与字距[1]。提取地理注记的位置与内容两个主要性质,忽略构成元素,其可以被形式化为:
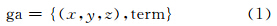
其中,(x,y,z)表示地理注记的空间位置 ;term为结构化词汇或数值,代表地理注记的内容。地图服务环境,结构化的term难以适应其描述需要,为此,用非结构化的文本替代term,并将这种地理注记形式称为宽泛地理注记(broad geographic annotation,BGA),描述为:
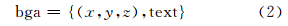
式中,(x,y,z)表示宽泛地理注记的空间位置;而text为文本内容,通常是以自然语言描述的非结构化文字段落。在英文行文中,单词之间是以空格作为自然的分界符,而中文只是在字、句、段层次上能够通过明显的分界符来划界,在词汇层次上没有一个形式上的分界符。因此,本文通过中文分词过程,将宽泛地理注记文本内容text描述为结构化的单词序列形式:

式中,由termi统计词汇出现频率,被认为是text的维度特征,能够有效支持text分类[8,9],即bga属于什么类型。事实上,构成文本的词汇数量是相当宠大的,因此,表示文本的向量空间也会很大。一些通用并普遍存在的词汇对分类的贡献较小,而某些词汇出现频率则相对不稳定,在不同文本类型中的特征差异明显,对分类的贡献较大。空间上,bga的作用范围是局部的,其空间位置(x,y,z)是构建局部范围的基准。 2 投放模型
在陆地表面绘制等高线是合适的,同样的绘制动作如果置于水体表面就不恰当或是不正确;类似地,在水体表面出现岛状地理实体是合适的,而如果出现代表建筑物实体的规则形状则是不恰当的。以上现象解释了投放过程的两个关键要素:投放对象与投放区域。评价投放过程的适宜性,必需将两个关键要素相结合,而不能割裂开来。将地理注记操作视为投放过程,投放模型如下所述。 2.1 宽泛地理注记词频分类
依据式(3),可以根据词汇出现的频率建立注记文本分类。即根据已有宽泛地理注记集BGA,得到基础词汇表(basic term table,BTT),形如BTT<term>。对于任意bga(bga 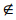 BGA),将bga.text中出现的所有词汇(term1,term2,…,termn)顺序地组成一个向量 e [ext1 ext2 … extn],其中,exti表示词汇termi是否存在于BTT中,如果存在,那么exti= 1,否则exti = 0。至此,宽泛地理注记的文本词汇存在分类可以被定义为:
BGA),将bga.text中出现的所有词汇(term1,term2,…,termn)顺序地组成一个向量 e [ext1 ext2 … extn],其中,exti表示词汇termi是否存在于BTT中,如果存在,那么exti= 1,否则exti = 0。至此,宽泛地理注记的文本词汇存在分类可以被定义为:

函数ec()将exti存在值为1的次数累加即可以确定所属分类,对于不同类型的BGAi与BGAj,则宽泛地理注记类型是函数值大的BGA类型。值得注意的是,存在分类只是考虑词汇存在与否的简单情况,将出现一次与出现n次的词汇对分类的影响视为相同作用,显然,出现n次的词汇在分类上的作用要大于出现一次的词汇。扩展基础词汇表为由已知类型宽泛地理注记集BGAi所得到的BTTi,形如BTTi<term,freq>。对于任意bga(bgaBGA),将bga.text中出现的所有词汇(term1,term2,…,termn)顺序地组成一个向量 v [freq1 freq2 … freqn],其中,freqi表示词汇termi在BTTi中的频率。如果存在多种类已知分类宽泛地理注记集{BGA1,BGA2,…,BGAn},那么,宽泛地理注记的词频分类可以被定义为:
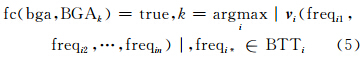
词频分类函数fc()的物理意义是,宽泛地理注记类型由距离其最近的已知注记集合类型所决定,距离则由向量 v 的模长度量。需要说明的是,如果bga.text的长度过长,会导致维数n过大,多个freq值较小的词汇会使模长值显著变小,导致不同类型之间的差异变小,影响分类精度,因此需要对bga.text进行降维处理,即选择freq值在不同BTT中差异较大的词汇构成向量。
关于已知宽泛地理注记集BGA类型,可参考《国家语委语料库》中的分类体系构建。语料库由3个一级分类(人文与社会、自然、综合)以及约40个二级分类构成,如果二级分类不够细致,可参考其他分类资料对其进行细分类。 2.2 Voronoi k阶邻近投放邻域
地理学第一定律指出“任何事物都是相关的,但相近的事物关联更紧密”[10]。邻域范围内的地理实体分布具有相似性,称其为空间自相关性。更加具体地,空间自相关性是指空间目标的属性受它的空间位置影响,是空间目标属性值聚集程度的度量。与此同时,邻域之间会出现行为不确定现象,如居民购买力与居民收入的关系,不同地区(经济发达、经济落后)之间差异较大,称其为空间异质。宽范地理注记的空间分布亦是服从这样的规律,在邻域内部由相同或相近的标注类型组成,表现出空间自相关性;在邻域之间,则存在标注类型的差异,表现出空间异质性。邻域内部的注记类型相同或相近,表现出空间自相关性;邻域之间的注记类型有所差异,表现出空间异质性。将宽泛地理注记的存在环境视为局部邻域,宽泛地理注记相互之间的位置构成邻域的自相关性,如图 1所示。

|
| 图 1 空间自相关邻域形成过程 Fig. 1 Sequential Process of Spatial Auto Correlation Neighborhood |
空间目标之间的位置邻近描述主要存在欧氏距离邻近与Voronoi邻近两种方法,相对于欧氏距离邻近,Voronoi邻近在邻近描述与邻近度量方面更具优势[11,12]。
定义1 Voronoi邻近:存在空间目标集合O
则称 oi与oj 为Voronoi邻近。
Voronoi邻近关系具有传递特性,可由多个步骤的Voronoi邻近-Voronoi距离定义,进而归纳出普遍意义下的Voronoi k阶邻近。
定义2 Voronoi k阶邻近:存在空间目标集合O
Voronoi邻近是Voronoi k阶邻近的特例,即当k=1时,Voronoi一阶邻近等价于Voronoi邻近。本文中,将宽泛地理注记的存在环境视为由Voronoi k阶邻近构成的局部自相关邻域,而自相关性的度量依据局部Moran指数统计量得到[13]。Moran指数是用于识别空间邻域自相关的有效方法,结合宽范地理注记类型向量,局部Moran指数统计量计算为:
其中,n为Voronoi k阶邻域中的空间目标数; |v i|是类型向量的模,是类型向量模的平均值;wij是权重矩阵W在i行j列的取值。观察可知,Moran指数的分子为邻域中所有注记目标类型向量的协方差之和,而其分母为所有注记目标的标准差之和,比值位于(-1,1)范围。当Ii>0时,表示邻域为正的空间自相关,且Ii值越大相关性越大;当Ii<0时,表示邻域为负的空间自相关;当Ii= 0时,则表示邻域为随机独立分布,化简式(7),得:
式中,z′i与 z′j是经过标准差标准化的注记向量;wij是权重矩阵W在i行j列的值,对于wij取值,为了保证空间权重矩阵W的外延性,根据注记目标之间的Voronoi邻近距离来度量,依据定义2,将wij赋值为注记目标bgai与bgaj的Voronoi k阶邻近距离,即
对邻域局部Moran统计值的计算结果采用随机分布或者近似正态分布进行验证,用标准化统计量 Z来检验n个邻域地理注记否存在空间自相关,统计量Z[14]的计算公式为:
其中,E(Ii)为均值;VAR(Ii)为方差。当Z>0且Ii>0时,表明存在正空间自相关,即是说相同类型地理注记在邻域中趋于聚集态势;当Z<0且Ii>0时,表明存在负的空间自相关,说明相同类型的地理注记在邻域中趋于分散态势;当Z=0时,则表明呈独立随机分布。
假设地理注记存在于具有正空间自相关性质的局部邻域中,由上述计算过程,可根据Voronoi k阶邻近依据阶数k值由小到大调整来动态构建邻域,收敛条件为Ii>0且Z(Ii)>0成立的最小k值,建立投放邻域(board geographic annotation region,BGAG)描述为:
2.3 投放过程
在已知地理注记数量较多的情况下,假设在局部邻域中,地理注记的分布呈注记文本正空间自相关形态,投放邻域由某一种类型的地理注记依照式(11)构建。对于投放域空间范围内只存在一种类型的地理注记,称为单类型邻域;而如果存在多种类型地理注记,则称为复合类型邻域。对于一个新投放的地理注记,按其是否与邻域类型(或复合邻域类型之一)相同分为两种情况,而邻域为单类型或复合类型又分为两种情况,则可分为4种完备的情况。如图 2所示,图 2(a)中新注记投放到与其类型一致的单类型邻域;图 2(b)中新注记投放到与其类型不一致的单类型邻域;图 2(c)中新注记投放到复合邻域,并且与复合邻域中某类注记类型一致;图 2(d)中新注记投放到复合邻域,并且与复合邻域中的任一种注记类型均不一致。
图 2(a)是图 2(c)的特例,新注记投放到与其类型相同的自相关邻域中,在类型数值的分布上,新注记的类型值不会使邻域类型均值、方差出现明显变化。所以,图 2(a)、2(c)投放过程是正常与合理的。图 2(b)是图 2(d)的特例,由于新注记的类型不同于邻域类型,因此,用空间自相关性去评价是没有意义的。根据地理学第一定律,认为新注记降维后类型值改变即是新注记与邻域相关,并以此为依据建立情况图 2(b)、2(d)的评价。
根据式(5),在词频文本分类中,将bga.text中出现的所有词汇(term1,term2,…,termn)顺序地组成一个向量 v =[freq1 freq2 … freqn]。其中,每个词汇在分类中的贡献是不同的,出现频率高的词汇对当前文本类型的作用大,相反,出现频率低的词汇作用小。根据freqi值的大小,对(freq1,freq2,…,freqn)作频率递减排列,得到向量 v ′=[freq′ 1 freq′ 2 … freq′ n],做降维函数ds():
其中,m为每次降低的维数,此处m=1。降维函数ds()通过删除频率最高的项,使得bga.text分类最大可能地由当前类型发生改变。
设邻域的类型集合为BGAG.CLS,对于任意新地理注记bga,满足下式条件的新地理注记将不能被投放。
式(13)的物理意义是:如果新注记类型不同于邻域类型,那么,对新注记降维处理;如果降维后的类型仍不同于邻域类型(如果相同,虽然新注记类型值不变,但降维后的词频向量类型发生改变,即由新注记类型转变为邻域类型,表明新注记与邻域有相关性,即其在这个邻域中的存在是合理的),那么,新注记不能被投放到这个邻域。
3 算例与分析
实验地理注记共两类,分别为云南省昆明市一环内574个餐饮、372个商务类型注记,每种类型预留50个注记作为分类验证。注记空间位置为WGS 84坐标系,采集形式为百度地图与手持GPS设备。注记文本来源于美食评论网与百度搜索,文本最小长度15个汉字、最大长度52个汉字,平均长度为34个汉字。中文基础词汇来源于搜狗输入法,最后更新日期为2013年7月,共计约110万个汉语词汇,包含最新出现的网络用词汇。经分词处理,餐饮类地理注记中文基础词汇为100 015个,单个词汇出现次数的范围为[375,1],即词频范围为[0.716,0.001];商务类地理注记中文基础词汇为95 310个,单个词汇出现次数的范围为[146,1],即词频范围为[0.453,0.001]。根据式(5),分别用6、10、14、18、22个词频构成的类型向量对两种预留注记做分类验证,分类准确率均大于94%,其中,14词频向量准确率为100%,说明选用词率值较大的14个词汇能够对两种地理注记类型做到最优的分类。
在图幅范围内,随机生成50个空间位置样点,并根据式(11)做基于Voronoi k阶邻域的收敛性分析,如表 1所示。50个样点中的42个在Voronoi 3阶邻近以内条件下达到收敛,构成的邻域具有显著正空间自相关性,也就是说,地理注记的空间分布并非是完全随机的,而是表现出相似类型之间的空间集聚。更加具体地,空间分布的联系特征是具有较高类型值的注记相对地趋于与较高类型值的注记相邻,或者较低类型值的注记相对地趋于与较低类型值的注记相邻。需要说明的是,样点中有8个位于图幅相对边缘,当邻近阶数增大时,邻近目标个数增加较少,致使其满足收敛条件时的邻近阶数k值较大,并且存在类型值大小的差异较大,其平均Ii
对投放模型进行验证,收集实验区范围内实际存在的132个住宿类注记,并做分词,构成24 500个基础词汇,选取其中50个注记进行14词频向量投放计算。依据式(12)降维后,50个住宿类注记均可以在实验区域内投放,其中,单个注记最多需要8次迭代降维后,其词频向量类型即可变化至邻域类型。如图 3所示,降维处理后的类型向量值发生显著变化,向量的邻域类型值均大于住宿类型值,由住宿类型指向其投放的邻域类型,根据式(13),可以被投放。
收集150个某特种工业的文本描述,做分词构成31 000个基础词汇,并构造50个特种工业类注记(在实验区域范围内实际并不存在),同样做14词频向量投放计算,如图 4所示。随机投放位置选择与降维处理,相对于其所投放的邻域类型,类型向量中的词频值非常低(接近0),虽然经过多次迭代降维,向量的邻域类型值均小于特种工业类型值,即不能通过降维后的类型向量与其邻域产生联系,因此,不能被投放。
针对网络地图服务环境中的地理注记适宜性评价问题,本文首先将传统地理注记结构化内容扩展为非结构化的文本,形式化宽泛地理注记,并用投放过程来模型化网络地图环境中的标注行为,依据词频分类方法确定地理注记的类型,根据Voronoi k阶邻域建立投放域定量空间相关性描述,进而结合文本分类与空间自相关构建基于地理注记类型的投放模型。实验结果表明,注记存在的自相关邻域是成立的,并且,在两种已知地理注记情况下投放模型能够有效地对新增地理注记进行适宜性评价。
在实际应用环境中,地理注记的类型是多样的,注记文本的收集会导致词汇的不均衡,使得注记分类变得不准确,需要进一步研究。
 vor (oi)、vor (oj)分别为目标oi与oj的Voronoi区域,如果下式成立:
vor (oi)、vor (oj)分别为目标oi与oj的Voronoi区域,如果下式成立:
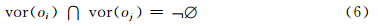 ,如果目标oi经过最小Voronoi邻近步数k(k ∈ N)到达目标oj,则称oi与oj为Voronoi k阶邻近。
,如果目标oi经过最小Voronoi邻近步数k(k ∈ N)到达目标oj,则称oi与oj为Voronoi k阶邻近。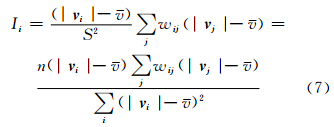
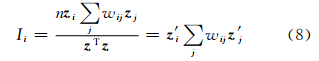

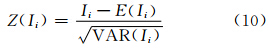
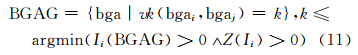

图 2 投放过程的4种情况
Fig. 2 Four Situations of Putting Progress
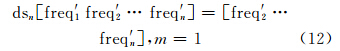
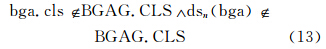
收敛k值 样点个数 平均Voronoi邻近目标数 Ti Z
1
9
5.6
0.53
3.41
2
17
14.2
0.54
3.43
3
16
40.7
0.54
3.46
4
8
20.3
0.50
3.21

图 3 住宿类地理注记类型向量值
Fig. 3 Vector Value of Accommodation Data Set

图 4 特种工业类地理注记类型向量值
Fig. 4 Vector Value of Special Industry Data Set
| [1] | Ma Yaofeng, Hu Wenliang, Zhang Anding, et al. Cartography Theory [M]. Beijing: Science Press, 2004 (马耀峰,胡文亮,张安定,等. 地图学原理[M]. 北京:科学出版社,2004) |
| [2] | Mirko H, Wilko H, Andrea M, et al. Automatic Annotation of Geographic Maps [C]. The 10th International Conference on Computers Helping People with Special Needs, Linz, Austria, 2006 |
| [3] | Zhang Xueying, Zhu Shaonan, Zhang Chunju. Annotation of Geographical Named Entities in Chinese Text [J]. Acta Geodaetica et Cartographica Sinica, 2012, 41(1): 115-120 (张雪英,朱少楠,张春菊. 中文文本的地理命名实体标注[J]. 测绘学报,2012,41(1):115-120) |
| [4] | Zhang Xueying, Zhang Chunju, Zhu Shaonan. Annotation of Geographical Spatial Relations in Chinese Text [J]. Acta Geodaetica et Cartographica Sinica, 2012, 41(3): 468-474 (张雪英,张春菊,朱少楠. 中文文本的地理空间关系标注[J]. 测绘学报,2012,41(3):468-474) |
| [5] | Wang Zhao, Wu Zhongheng, Fei Lifan, et al. Automatic Name Placement of Area Feature: A Metric Information Approach [J]. Acta Geodaetica et Cartographica Sinica, 2009, 38(2): 183-188 (王昭,吴中恒,费立凡,等. 基于几何信息熵的面状要素注记配置[J]. 测绘学报,2009,38(2):183-188) |
| [6] | Wu Changbin, Lv Guonian, Liu Yujun. Automated Numeric Placement for Land Utilization Map Based on Rule Database and Grid Algorithm [J]. Acta Geodaetica et Cartographica Sinica, 2008, 37(2): 250-255(吴长彬,闾国年,刘昱君. 基于规则库和网格算法的土地利用现状图自动数字注记[J]. 测绘学报,2008,37(2):250-255) |
| [7] | Chen Rui, Zhang Zuxun, Zhang Jianqing. Identification of Digital Elevation Annotation in Scanned Map [J]. Geomatics and Information Science of Wuhan University, 2002, 27(2): 194-198 (陈睿,张祖勋,张剑清. 扫描地形图中数字高程注记的提取与识别[J]. 武汉大学学报·信息科学版,2002,27(2):194-198) |
| [8] | Xie Chongfeng, Li Xing. A Sequence-Based Automatic Text Classification Algorithm [J]. Journal of Software, 2002, 13(4): 783-789(谢冲锋,李星. 基于序列的文本自动分类算法[J]. 软件学报,2002,13(4):783-789) |
| [9] | Zhou Qian, Zhao Mingsheng, Hu Ming. Study on Feature Selection in Chinese Text Categorization [J]. Journal of Chinese Information Processing, 2004, 18(3): 17-23 (周茜,赵明生,扈旻. 中文文本分类中的特征选择研究[J]. 中文信息学报,2004,18(3):17-23) |
| [10] | Tobler W. A Computer Movie Simulating Urban Growth in the Detroit Region [J]. Economic Geography, 1970, 46(2): 234-240 |
| [11] | Chen Jun. Voronoi-Based Dynamic Spatial Data Model [M]. Beijing: Publishing House of Surveying and Mapping, 2002 (陈军. Voronoi动态空间数据模型[M]. 北京:测绘出版社, 2002) |
| [12] | Zhao Renliang. Voronoi Methods for Computing Spatial Relations in GIS [M]. Beijing: Publishing House of Surveying and Mapping, 2006 (赵仁亮. 基于Voronoi图的GIS空间关系计算[M]. 北京:测绘出版社,2006) |
| [13] | Zhang Chaosheng, Luo Lin, Xu Weilin, et al. Use of local Moran's I and GIS to Identify Pollution Hot-spots of Pb in Urban Soils of Galway, Ireland [J]. Science of the Total Environment, 2008, 398(1-3): 212-221 |
| [14] | Shi Yimin. Mathematical Statistics (3rd Edition) [M]. Beijing: Science Press, 2009 (师义民. 数理统计(第三版)[M]. 北京:科学出版社,2009) |